用户使用手册
用户登录成功后,可以看到系统页面分为四部分:左上方为系统功能菜单,左中为应用模板列表“科学计算”,左下方为“人工智能”,右上方为系统资源等信息。如下图所示:

数据管理
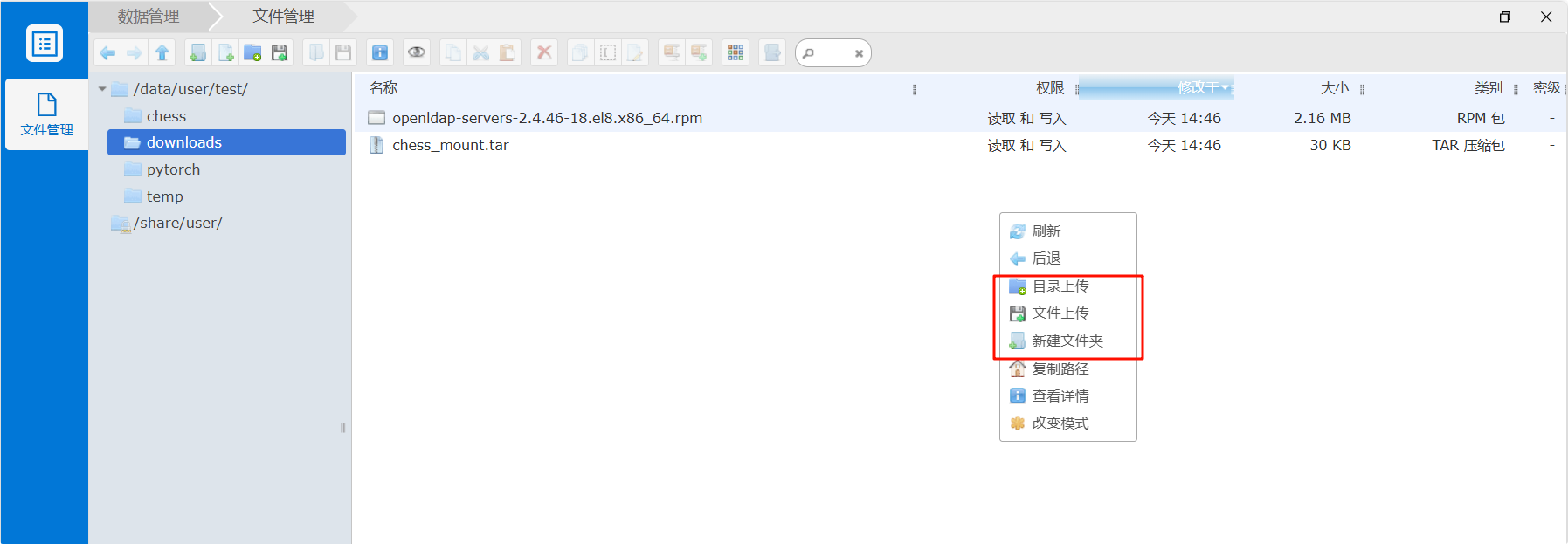
登陆平台后选择左侧的数据管理,会展开数据管理页面,在页面上点击右键即可实现文件、目录的上传与下载: 1) 文件、目录上传
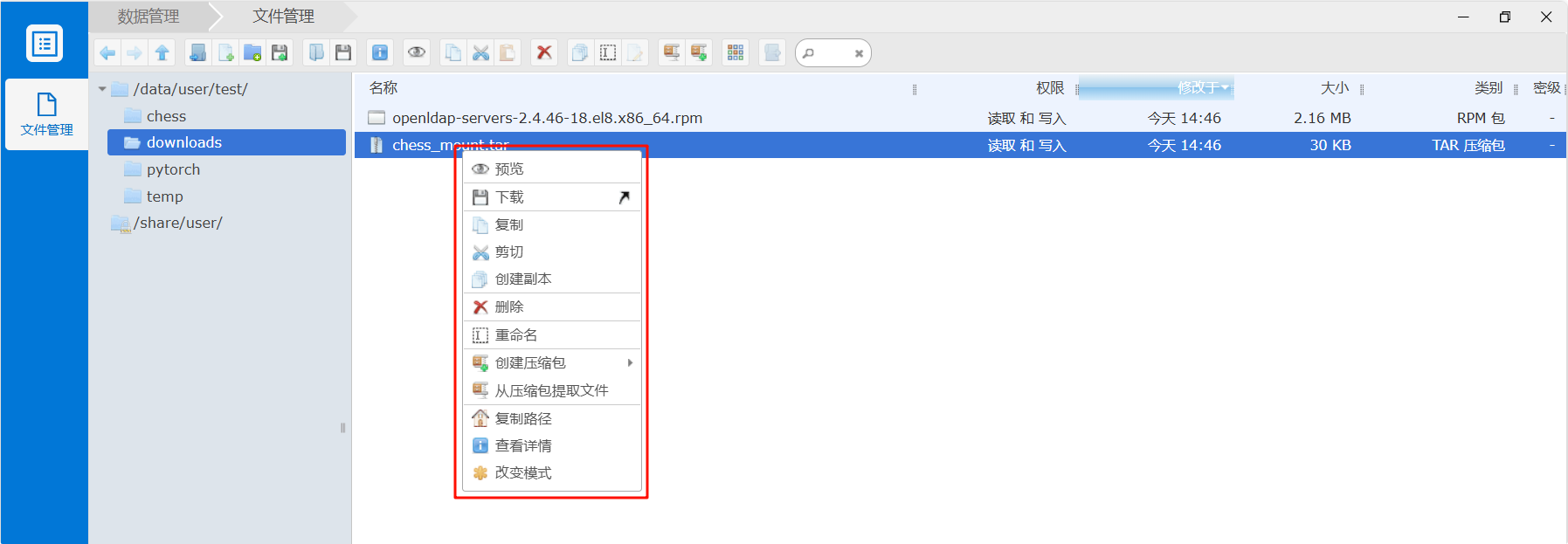
2) 文件、目录下载
应用中心
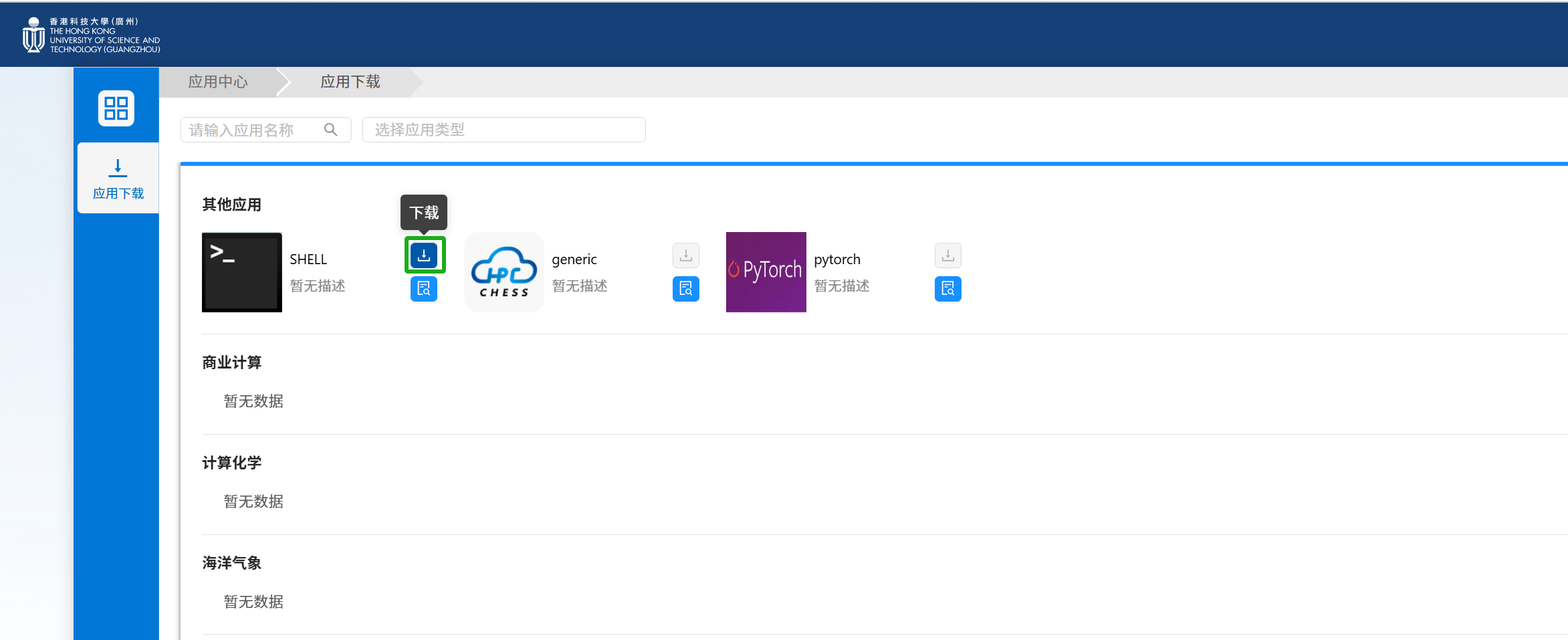
1) 如果桌面没有对应软件的图标,则需要在应用中心下载所需软件模板。点“应用中心”的图标,进入应用下载页面。如下图所示:

2) 下载应用:在应用中心中,点击应用软件模板旁的下载按钮。即可把该应用显示在用户的首页中。
作业管理
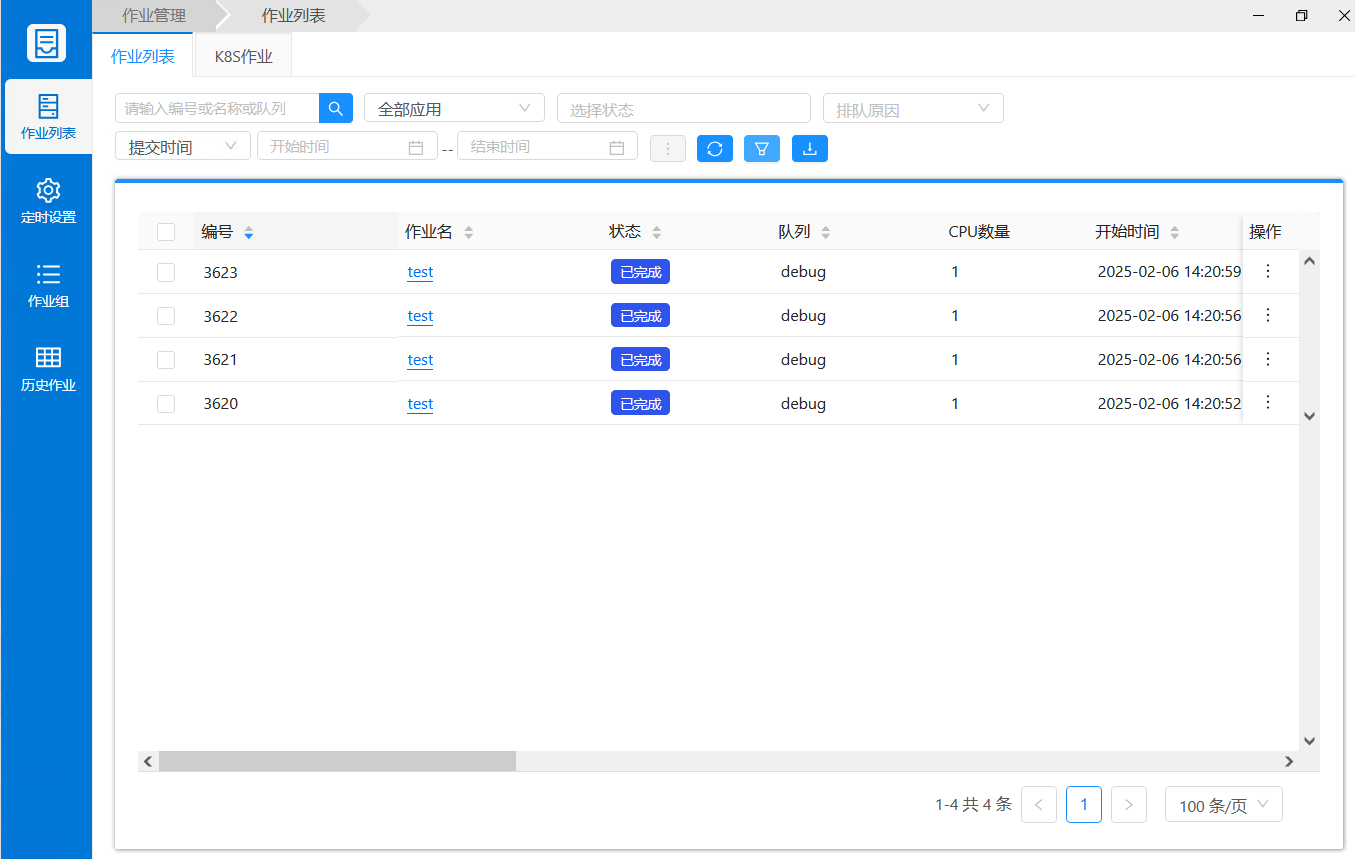
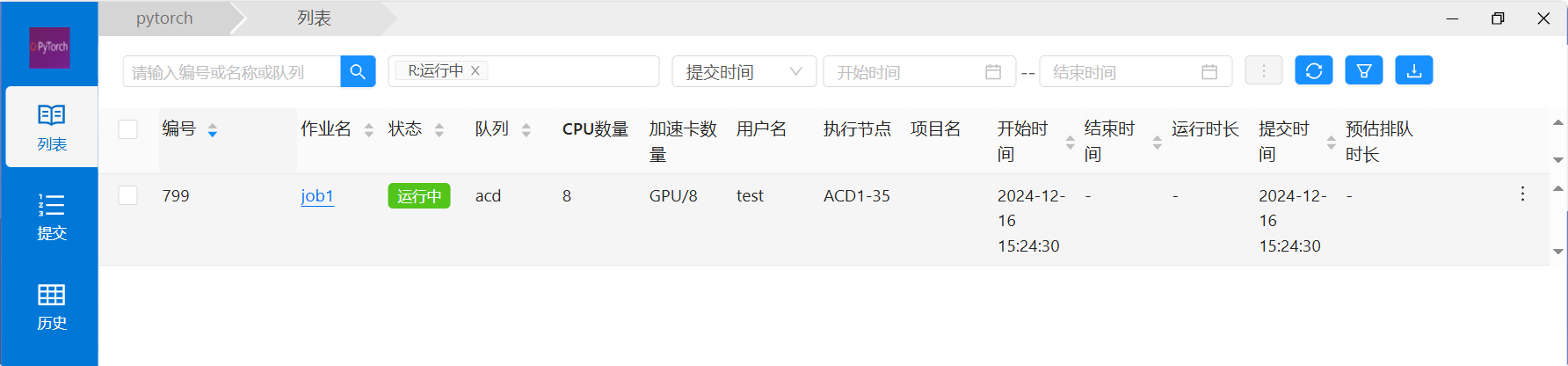
1) 作业完成后,在【作业管理】的列表里可以查看HPC和AI的作业信息。如下图所示:
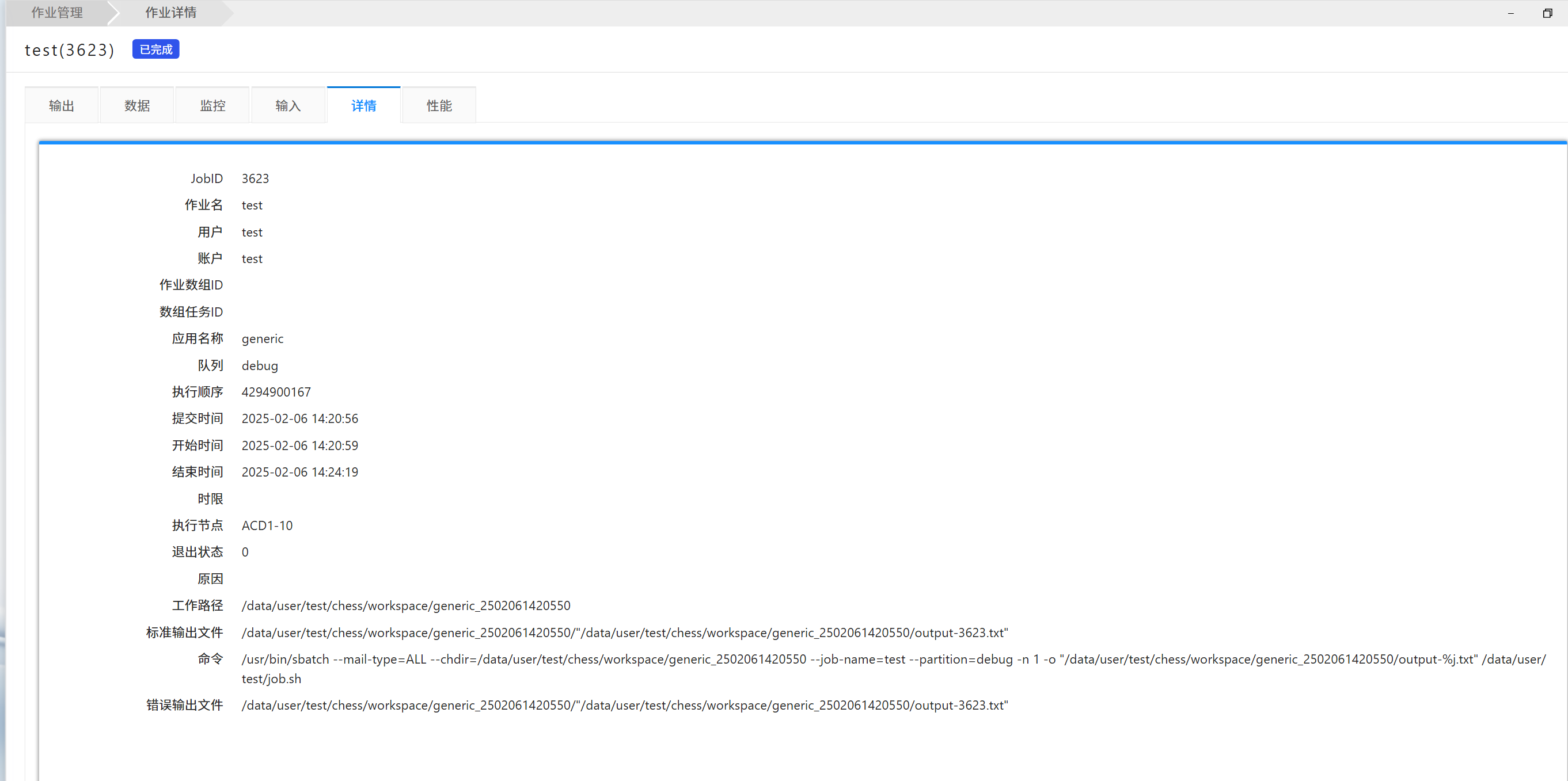
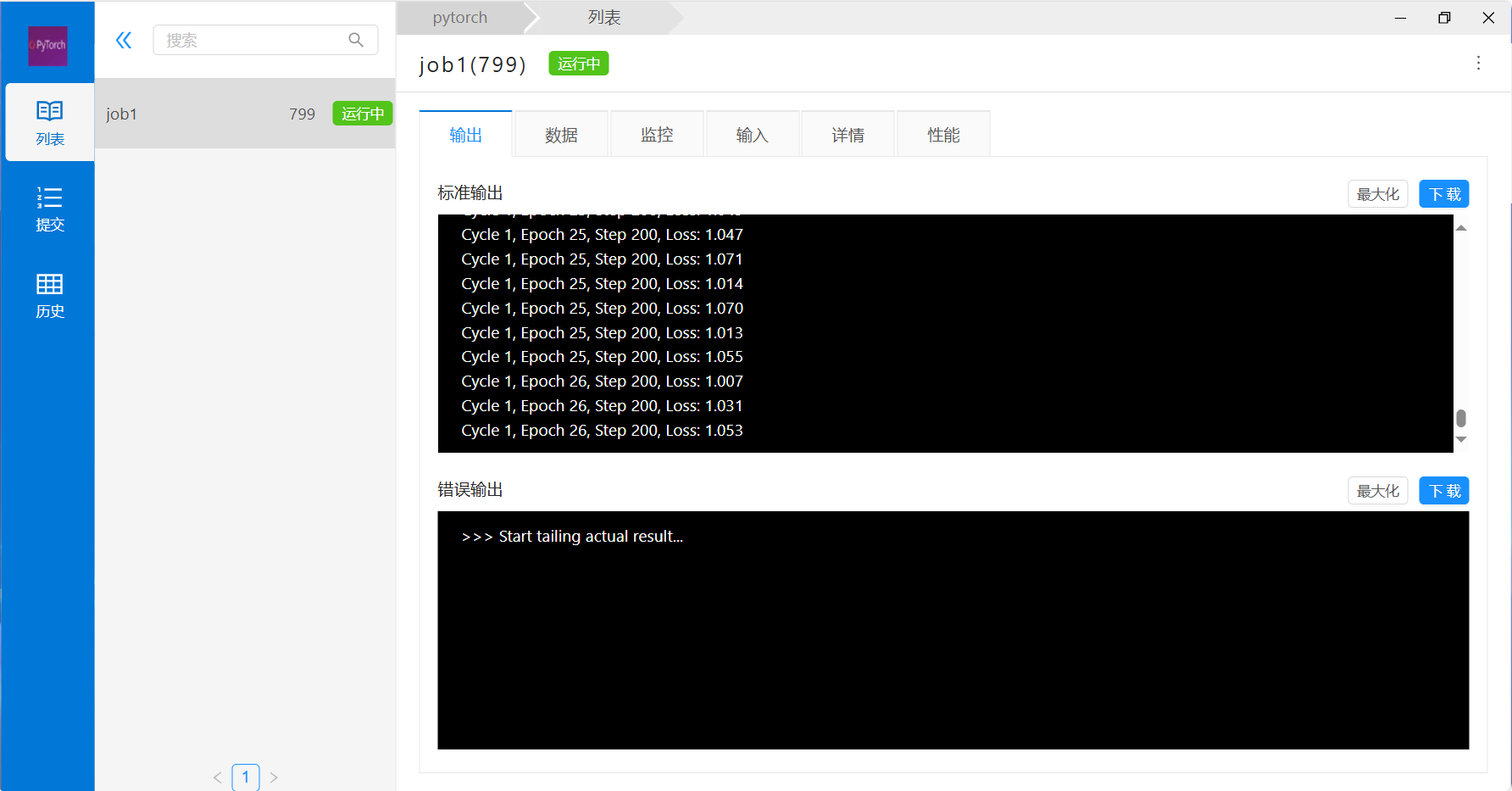
1) 点作业列表的作业名称,进入作业详情菜单,切换“输出”,“监控”,“详情”等标签,可以查看作业对应的信息。
作业列表支持模糊搜索和过滤,搜索条件依次为作业编号、作业状态下拉列表、现有数据时间段、时间选择框、排队原因等: 作业状态下拉列表:提供 运行中,排队中,已完成等作业状态供用户选择; 提交时间段:提示用户现有数据的时间跨度,为用户选择时间阶段提供参考条件; 时间选择框:便于筛选特定时间段的数据; 排队原因下拉列表:当前排队状态的作业原因汇总展示,无排队作业时,此下拉列表无选项展示。 下载Excel:将筛选结果保存到本地; 编辑列:排除几项默认必须展示的列外,用户可以自己编辑想要展示的其他列。
资源查看
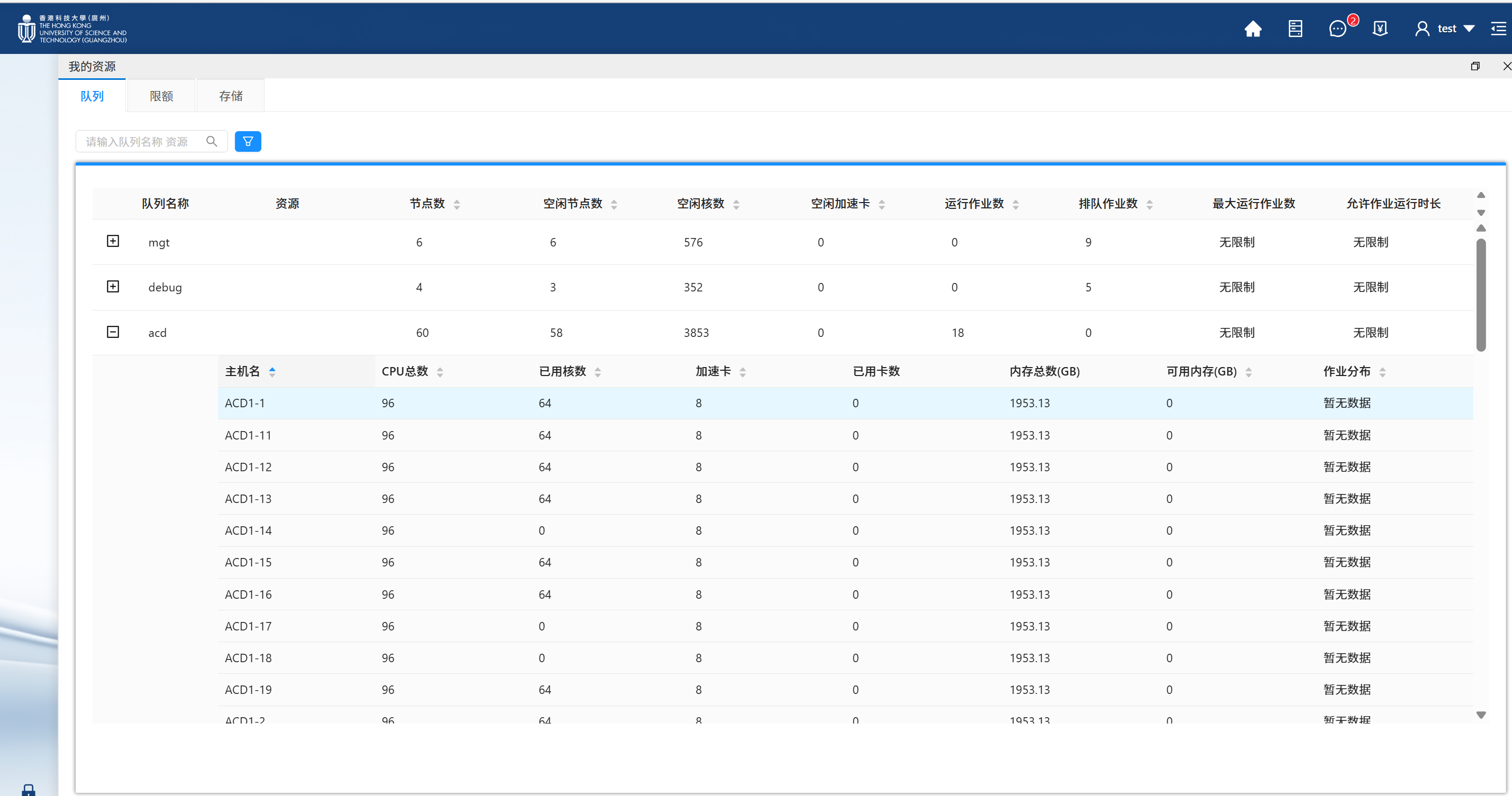
1) 登录集群后点击页面右上角“我的资源”。

2) 查看平台剩余资源信息
科学计算
基于web+slurm的训练任务提交方式
以pytorch软件为例,网页端任务的提交步骤如下: 1) 通过WEB界面的数据管理,将pytorch的算例文件,上传到集群自己的家目录中(注意请在一个文件夹里)
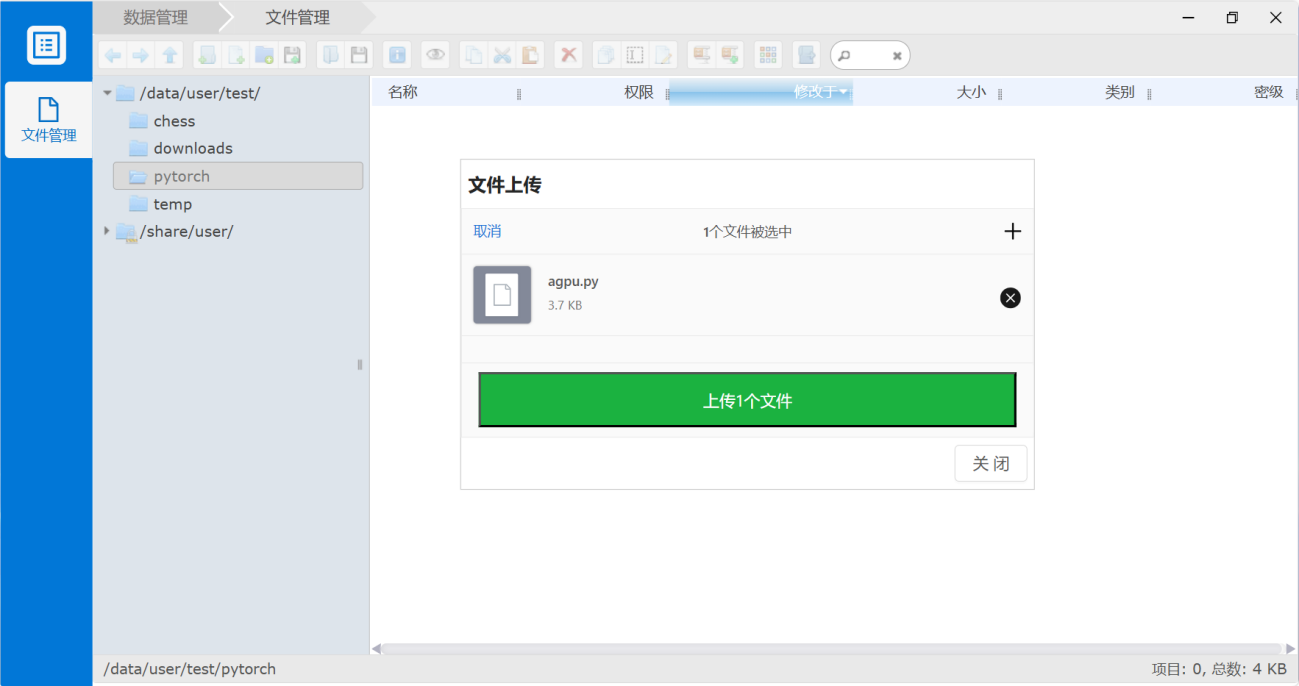
2) 选择pytorch对应的图标进入:
3) 点开pytorch图标后,默认位于“列表”栏,点选下放的“提交”图标
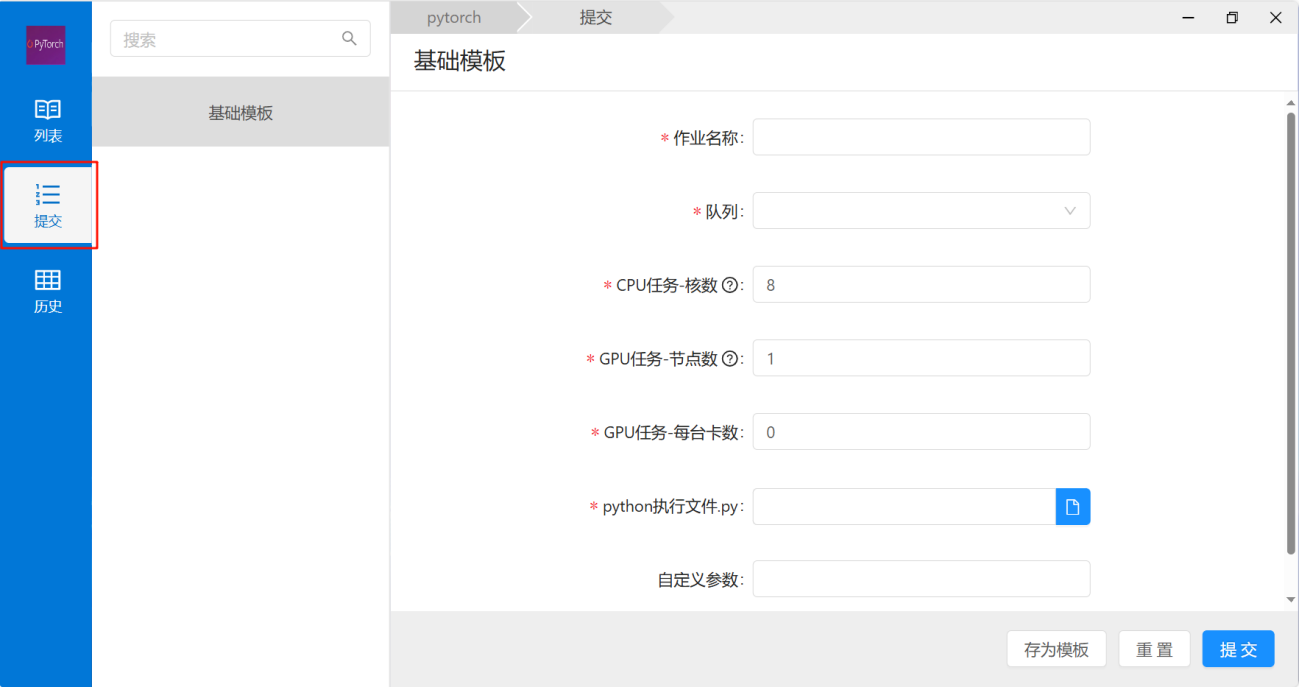
4) 参数填写:
- 作业名称:填写当前作业名称,但是不能包含中文、空格、特殊字符;
- 队列:队列选择acd队列;
- CPU任务-核数:程序执行时所需的核心数量;
- GPU任务-节点数:程序执行时所需的主机数量;
- GPU任务-每台卡数:选择每个节点所需gpu卡数;
- python执行文件:选择pytorch程序执行的python文件;
- 自定义参数:如需其他python参数直接填入,如没有则不用填写。
5) 参数填写完成后,点击“提交”,即完成提交。
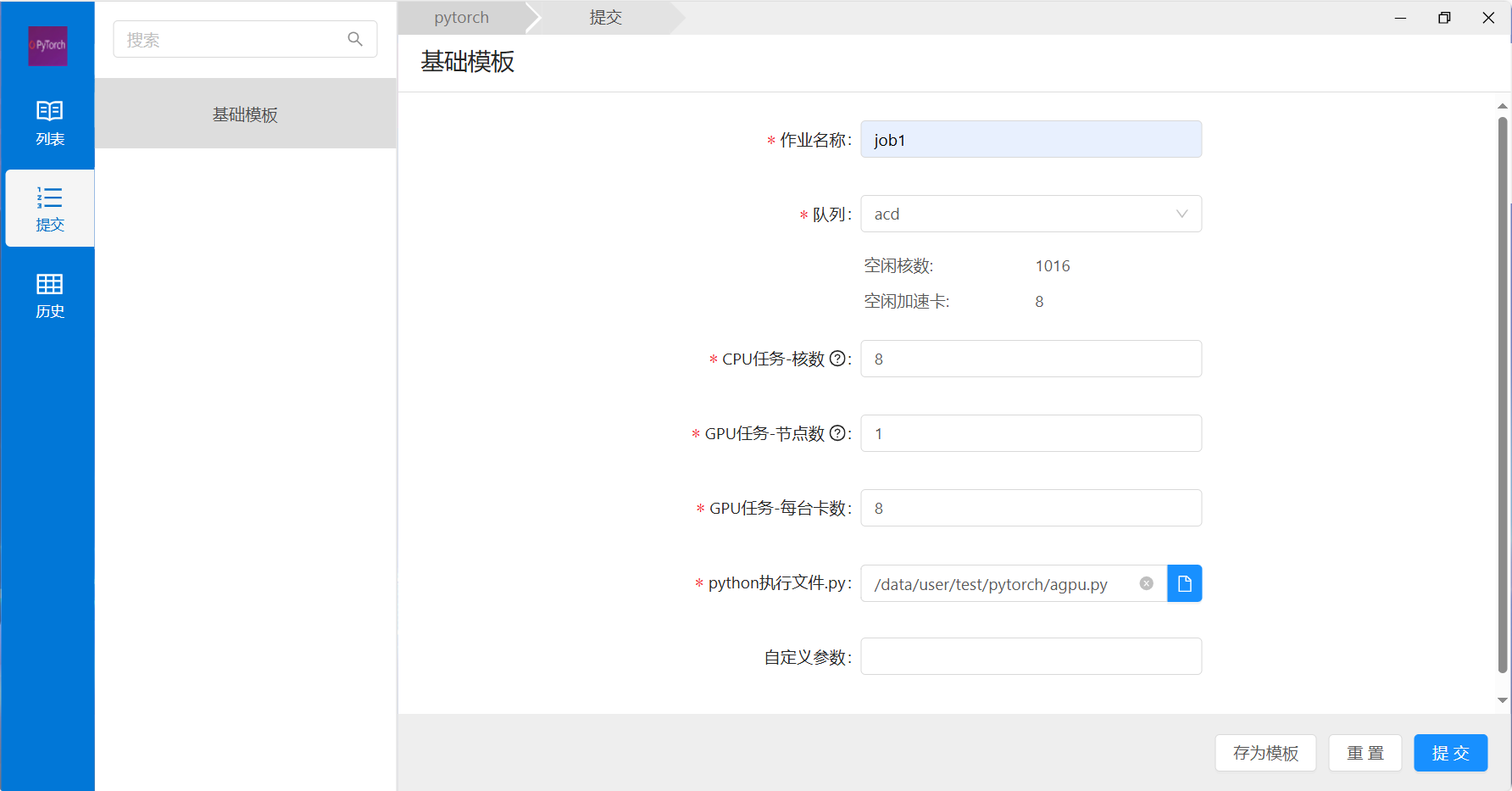
其中带红色*项目为必填项目。
6) 提交成功后,会在WEB页面顶部提示作业成功提交,可点击链接进入列表界面进行作业管理,或通过左侧的作业管理进入和查看该作业的情况:
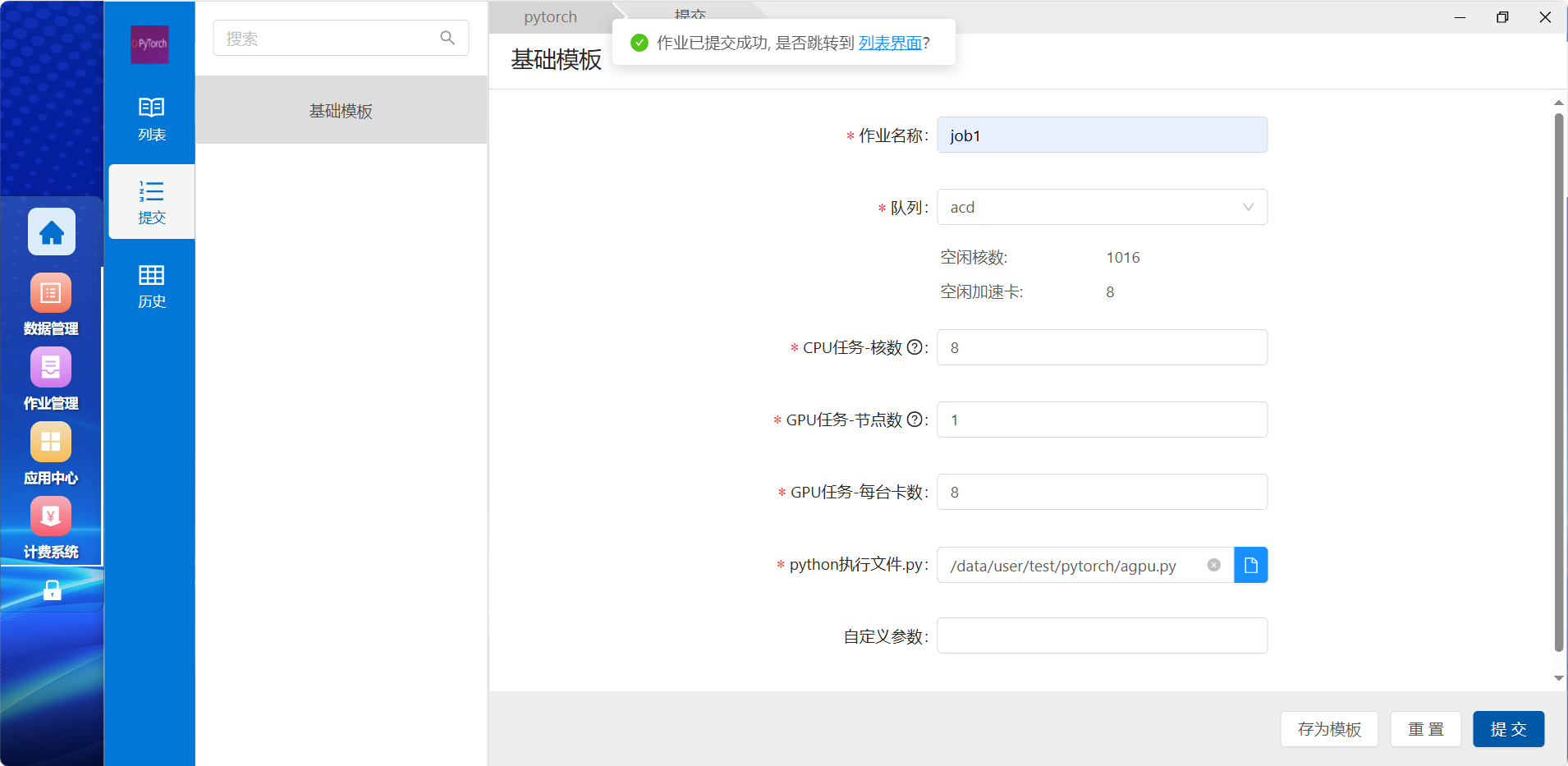
7) 点击对应运行的作业名称,即可进改作业查看详情、CPU使用情况及作业汇总信息等功能,点击“ ”即可进行作业的删改停操作。
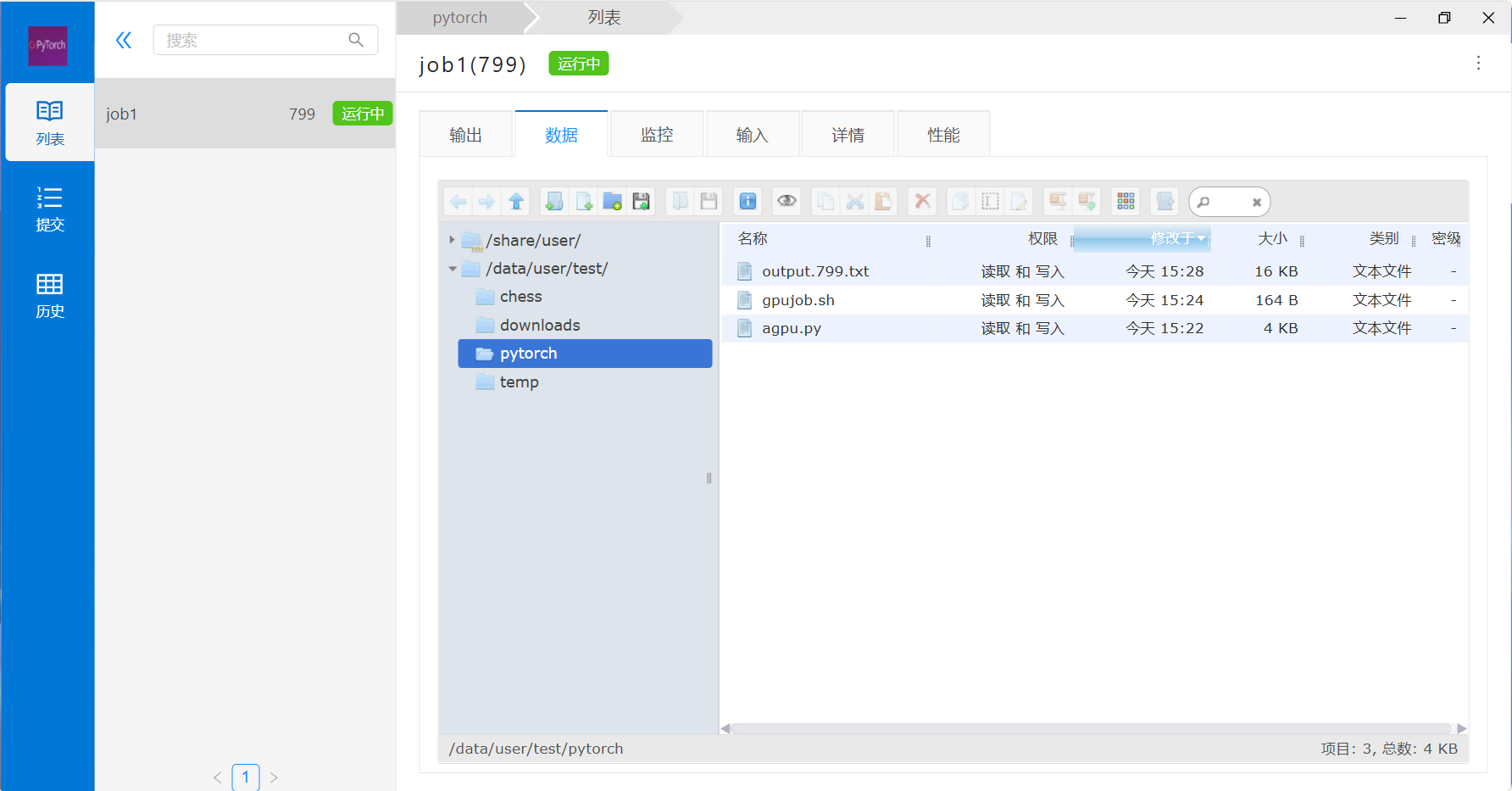
8) 等计算结束,即可通过该作业的列表链接进入数据管理或通过数据管理找到对应的数据进行下载和后处理分析。
基于cmd+slurm的训练任务提交方式
以Pytorch软件为例,使用命令行提交任务的步骤如下:
1) 打开Shell应用模板
2) 将算例文件agpu.py上传到Pytorch文件夹中

3) sinfo 命令用于查询集群中各分区节点的空闲状态和资源信息。squeue 命令用于查看提交作业的排队情况和作业队列信息。

4) sbatch提交任务,使用squeue命令查看任务状态。

5) 使用scancel jobid可以取消已提交的任务。
![]()
人工智能
用户登录成功后,点击“人工智能”模块的应用,可以进入到相应页面,如下图所示:

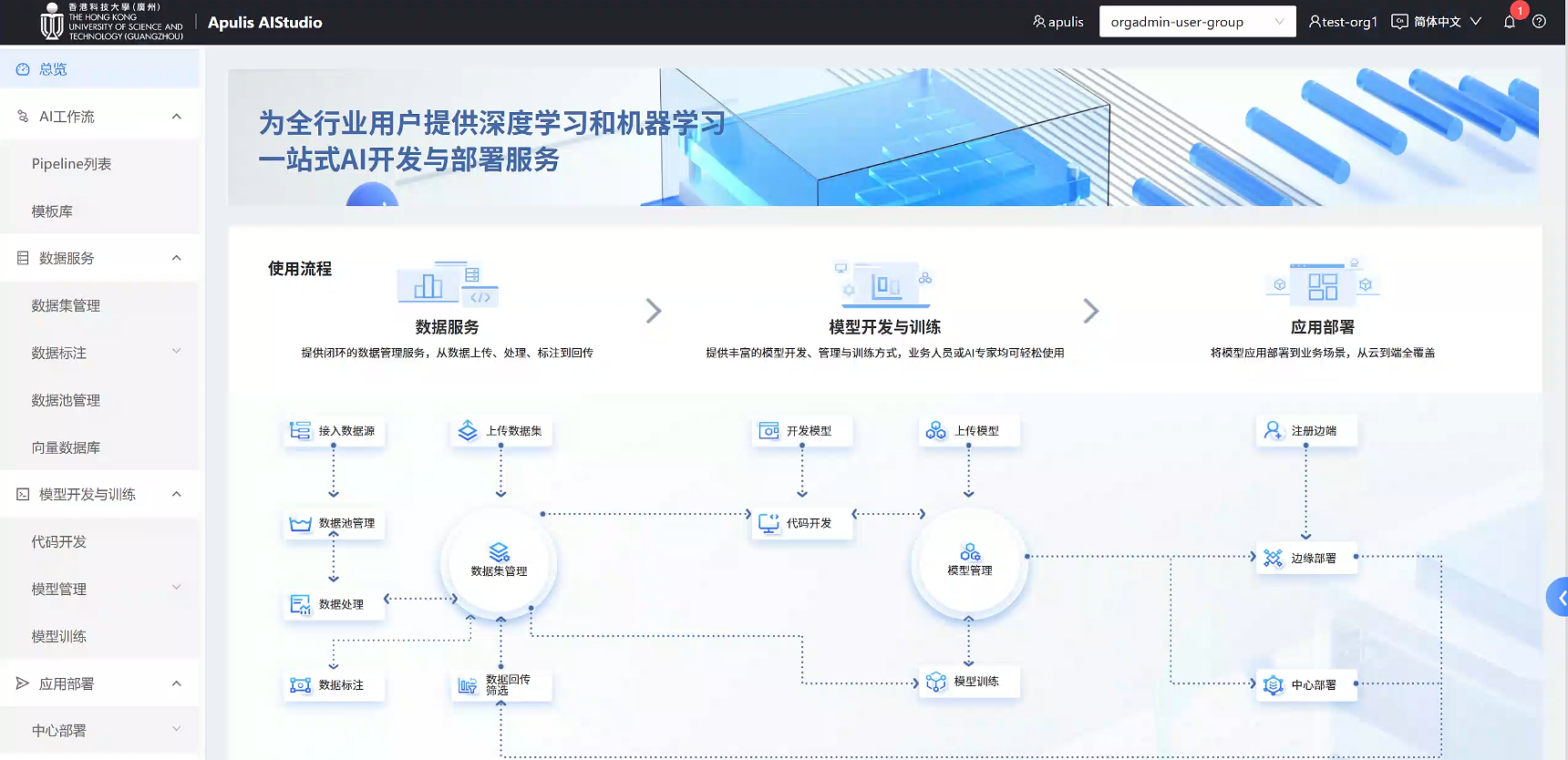
1 操作流程
Step 1: 准备数据。准备好目标检测相关的数据集、代码、镜像。
Step 2: 代码开发(可选)。使用平台环境进行代码开发和调试。
Step 3: 模型训练。创建模型训练任务,将优化后的模型发布到模型库。
Step 4: 应用部署。将模型部署为在线推理服务。
Step 5: 服务调用。使用API进行服务调用,并回传推理结果。
常见的使用场景如下所示,您可以按照流程引导,使用功能模块。
场景一:代码开发
在平台从0到1开发算法代码,或基于已有算法代码进行二次开发。
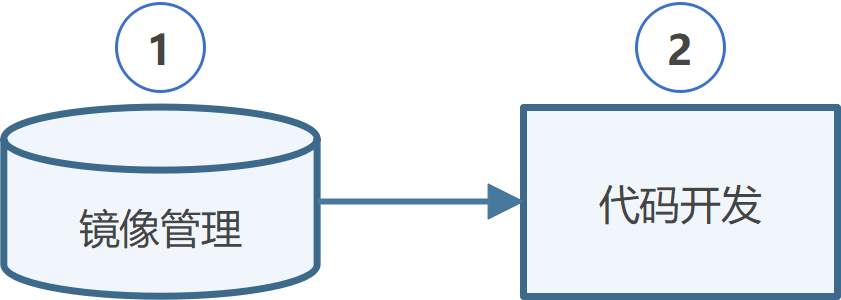
| 序号 | 功能模块 | 描述 |
|---|---|---|
| 1 | 镜像管理 | 管理用于运行代码开发环境的容器镜像,支持镜像上传、构建、版本控制 |
| 2 | 代码开发 | 提供代码开发环境和工具,支持使用平台纳管的计算资源进行从0到1的代码开发,或基于已有代码二次开发 |
场景二:模型训练部署 使用已有算法模型,在平台进行模型训练、评估和部署。
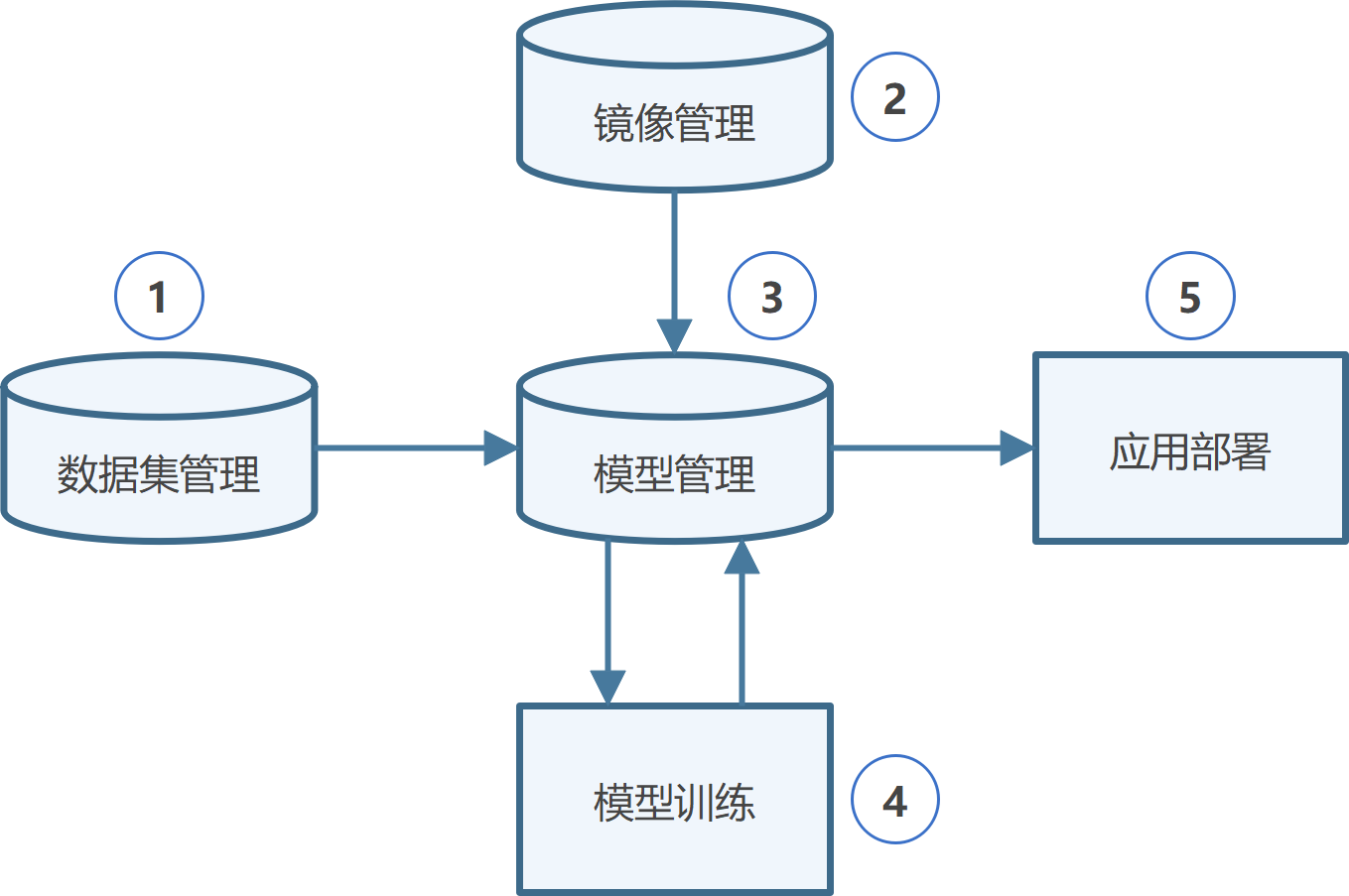
| 序号 | 功能模块 | 描述 |
|---|---|---|
| 1 | 数据集管理 | 管理和组织用于训练和测试模型的数据集,包括数据上传、标注、预处理和版本控制 |
| 2 | 镜像管理 | 管理用于运行模型的容器镜像,支持镜像上传、构建、版本控制 |
| 3 | 模型管理 | 管理不同版本的模型,支持模型的上传、版本控制、元数据管理、训练/评估/推理配置 |
| 4 | 模型训练 | 配置和启动模型训练、评估任务,监控训练过程,支持分布式训练和调参 |
| 5 | 应用部署 | 将训练好的模型部署为在线服务或嵌入到应用中,提供API接口,支持负载均衡、推理结果回传 |
下面将以通用目标检测任务为例,介绍如何使用平台进行开发、训练和部署目标检测模型。
2 准备数据
首先,需要准备用于模型训练评估的数据集、目标检测模型的算法代码、以及支撑模型运行的镜像。
2.1 准备数据集
本案例中使用COCO 2017数据集。COCO 2017 是一个广泛用于目标检测、实例分割和图像描述等计算机视觉任务的大型数据集,包含训练集、验证集和测试集,共计约 16 万张图像,涵盖 80 个物体类别,例如人、汽车、动物、家具等。平台已预置此数据集。
查看预置的数据集
登录平台后选择“人工智能>数据服务>数据集管理”,会展开数据管理页面。
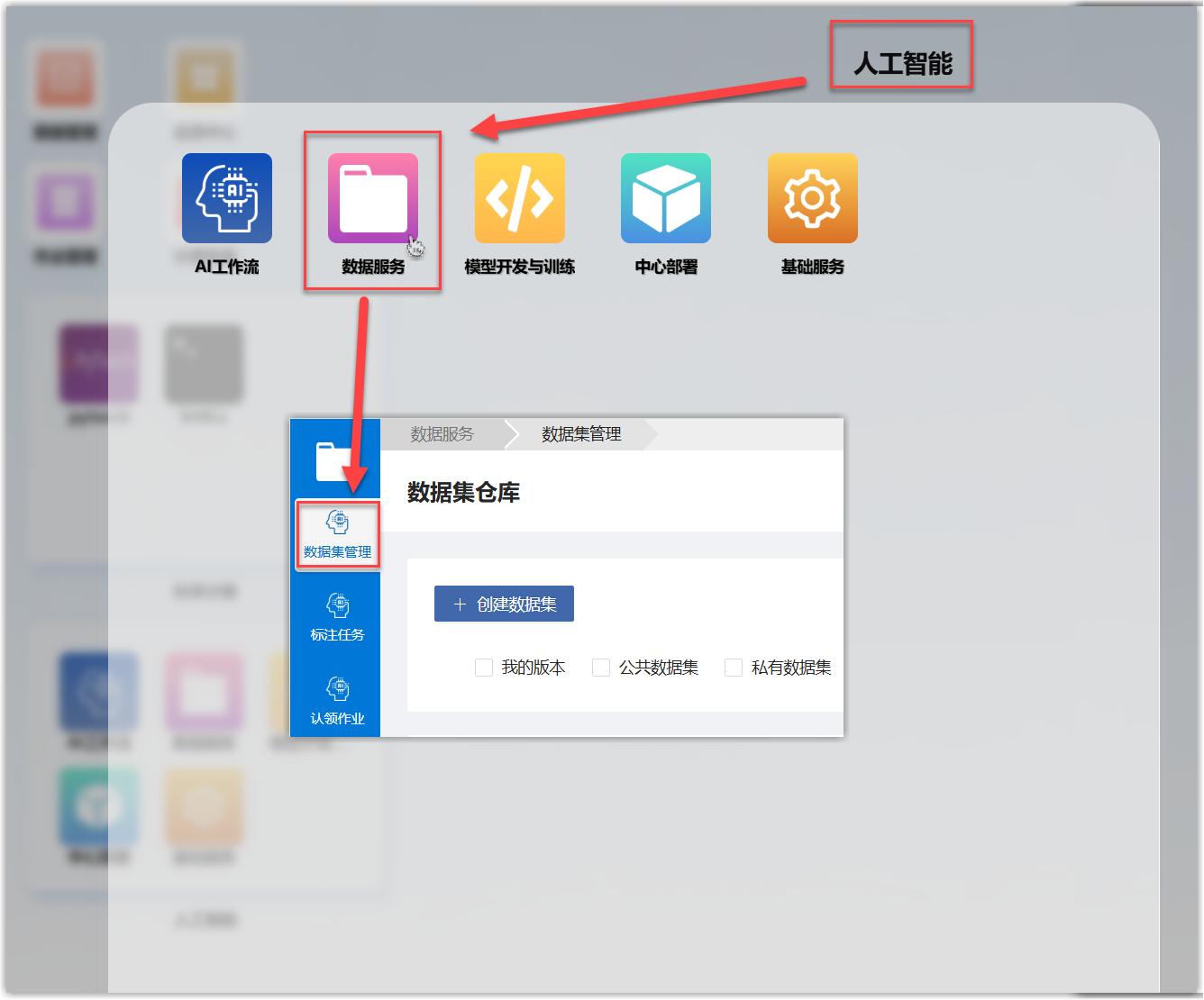
搜索数据集名称“coco”,找到对应的预置数据集“coco2017”,包括:
- 训练集 (coco2017_train): 包含约 118,000 张图像,用于训练模型。
- 验证集 (coco2017_val): 包含约 5,000 张图像,用于在训练过程中验证模型的性能。
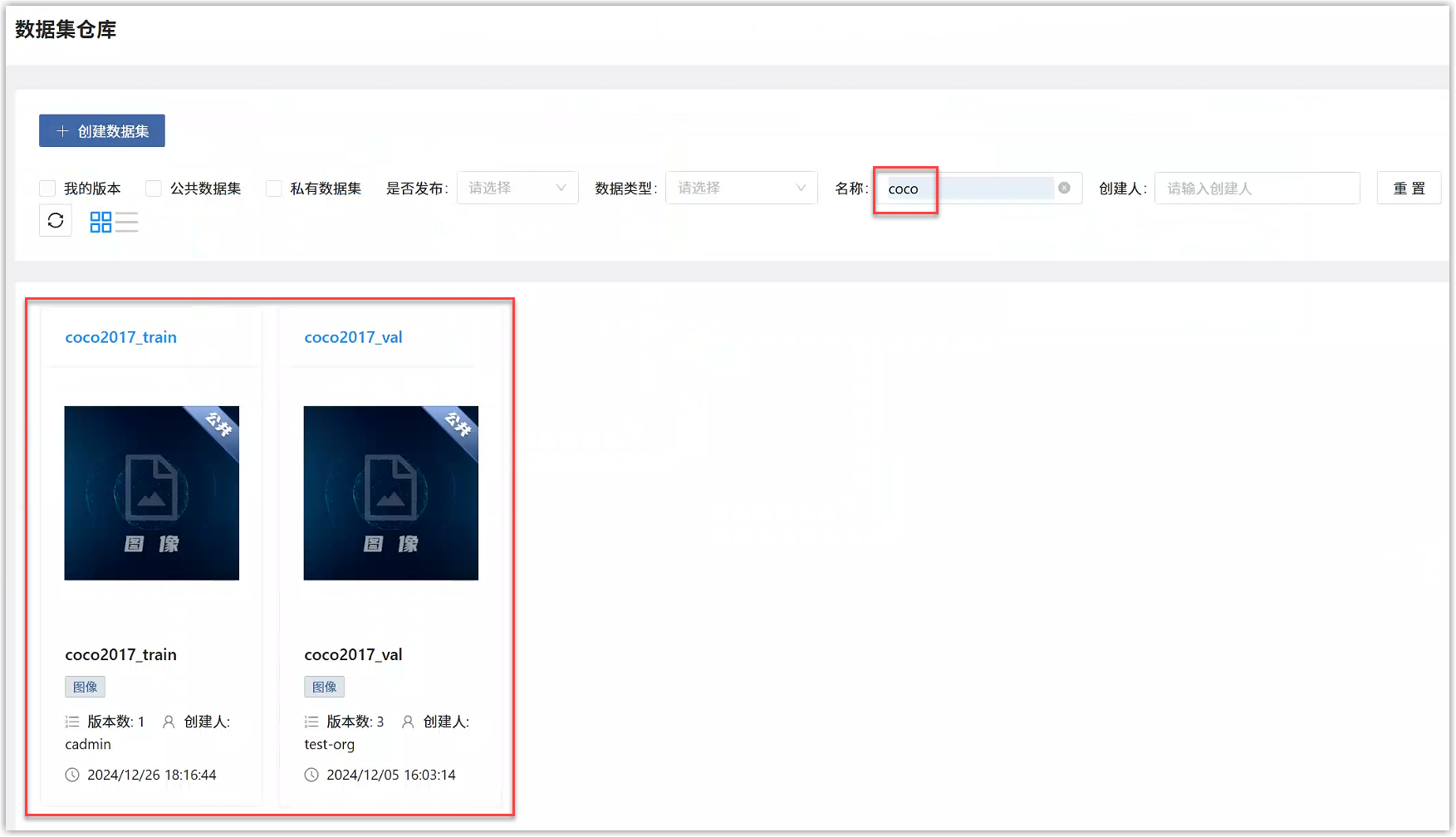
点击数据集,进入数据集详情。
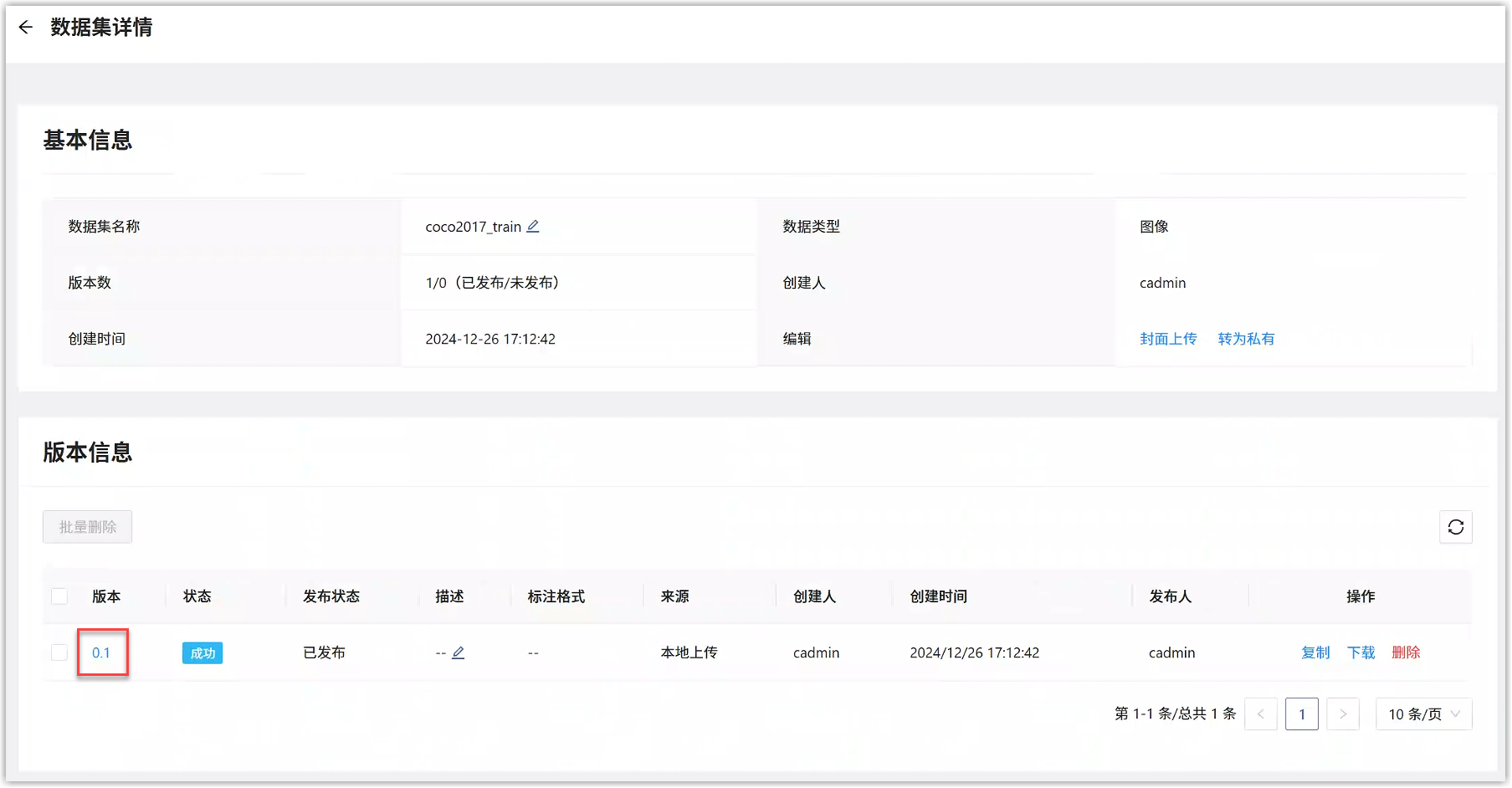
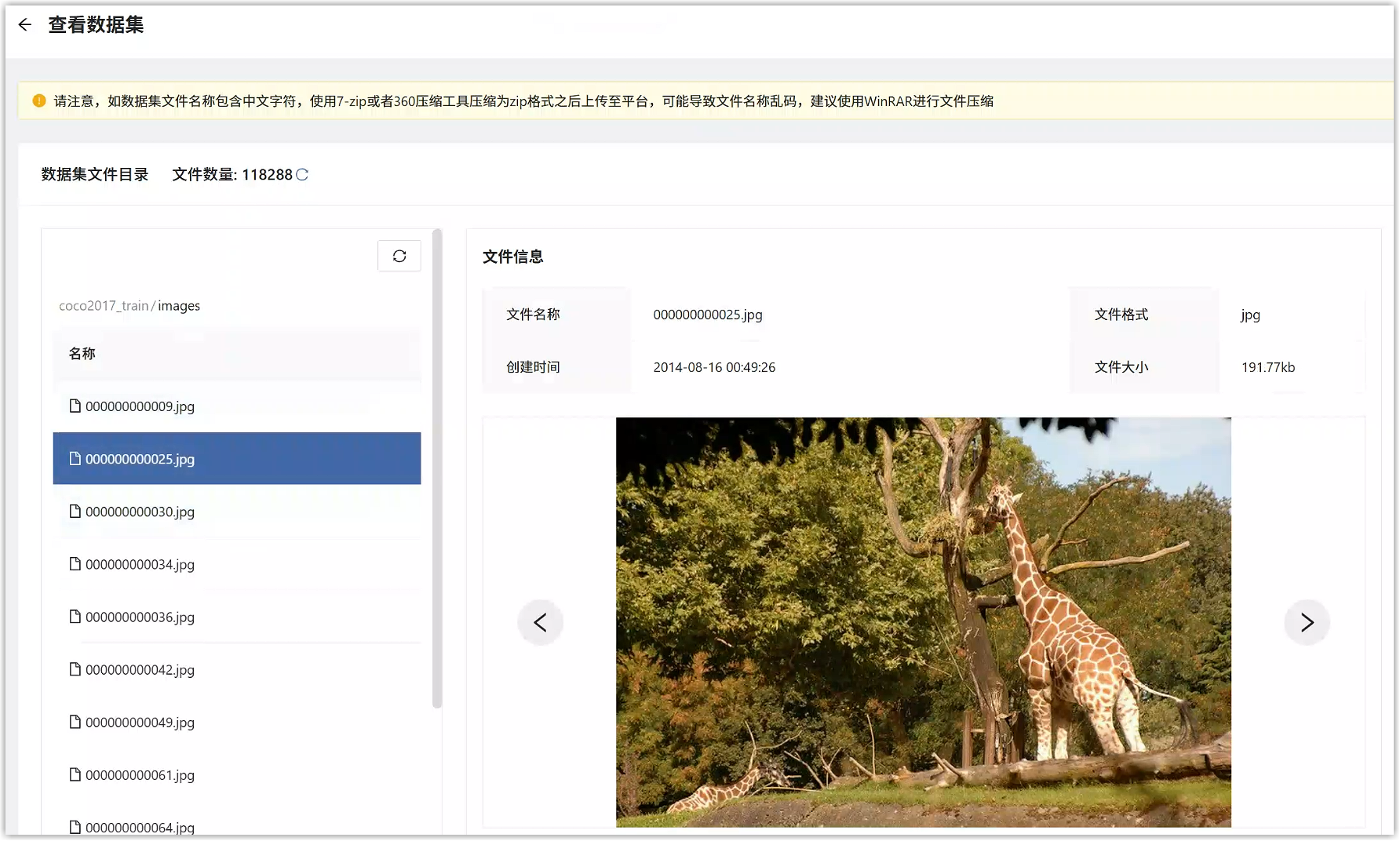
点击版本号,可以查看具体数据内容。
上传数据集
您可以将自己的数据集上传到平台。左侧导航栏“数据服务>数据集管理”,在数据集仓库页面点击“创建数据集”按钮。
进入创建数据集页面,填写如下信息。
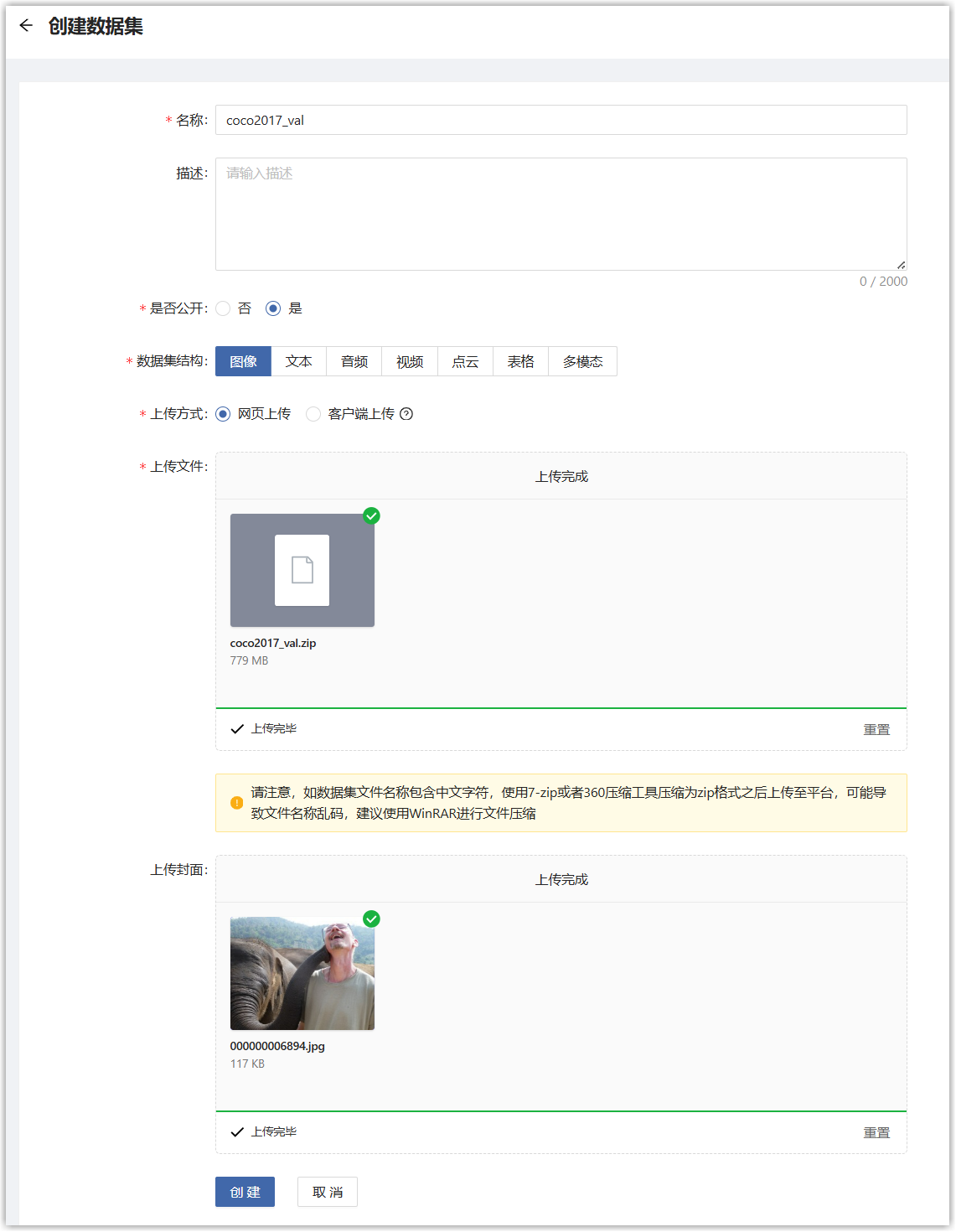
单击“创建”按钮,页面跳转到数据集仓库页面,点击刚才创建的数据集名称,进入详情页面,可以看到自动新建了0.1版本,状态为“创建中”,等待状态变为“成功”后,即完成了数据集上传。
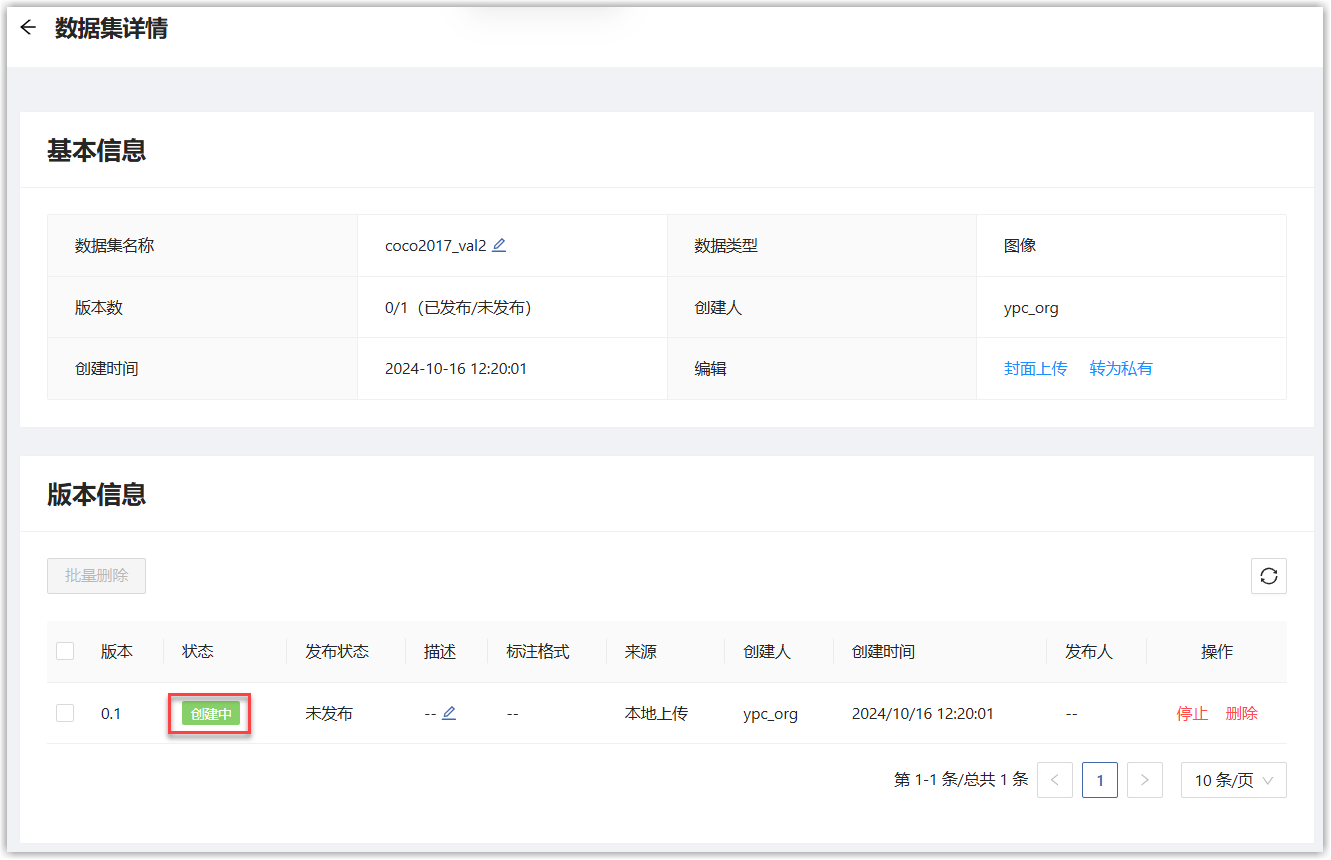
2.2 准备算法代码
本案例中使用YOLOv11算法进行目标检测。YOLOv11是一种高效、准确的目标检测算法,能快速识别图像或视频中的多种物体。平台已经预置了此算法模型。
查看预置的算法模型
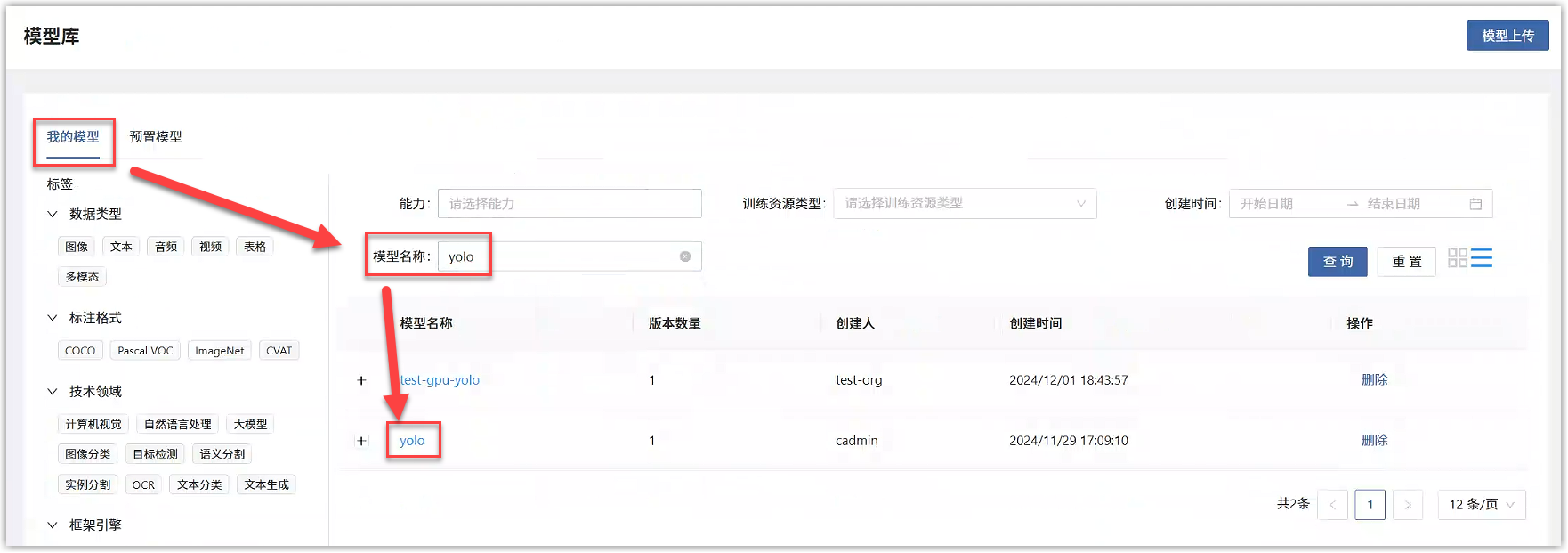
用户主页选择“人工智能>模型开发与训练>模型库”,会展开模型库页面。
在我的模型标签页中,搜索预置模型名称“yolo”,找到对应的预置模型“yolo”。点击模型名称,进入模型详情。
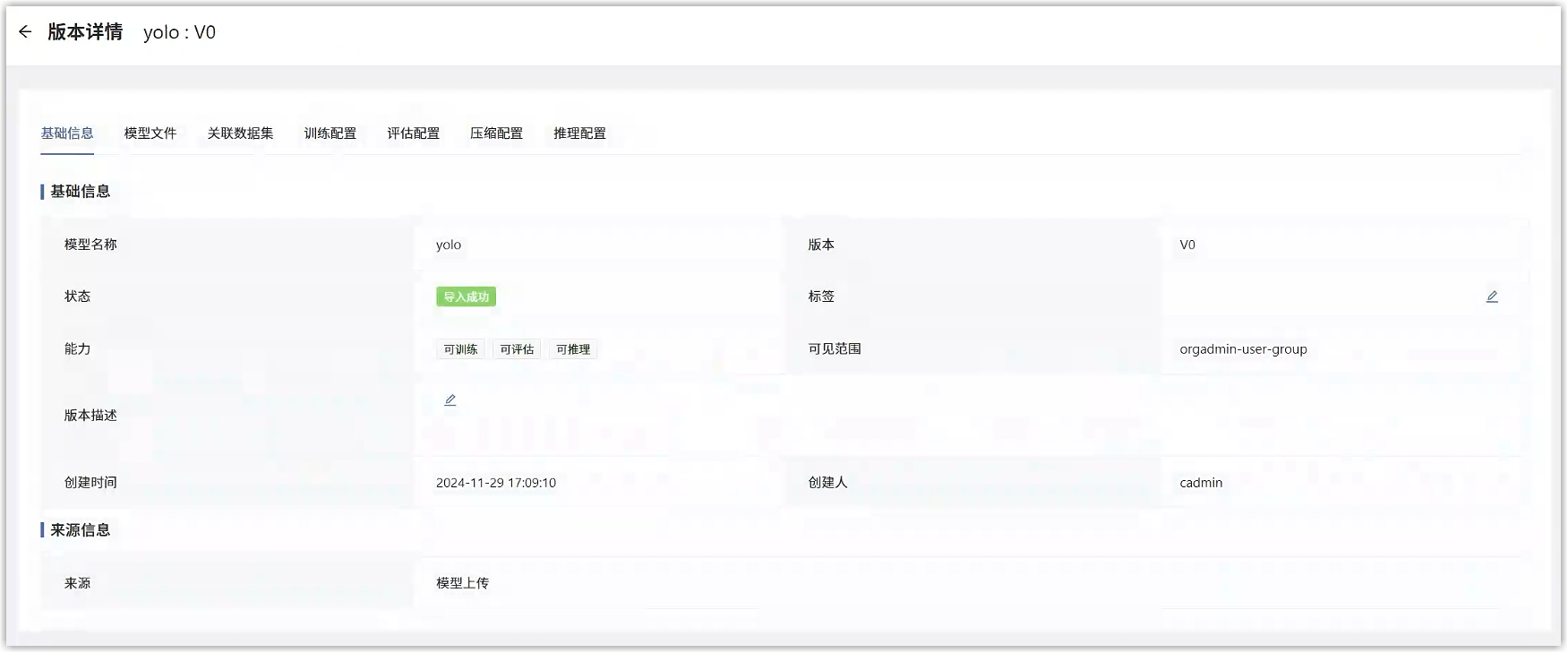
模型详情页面,点击对应的版本号,进入版本详情。
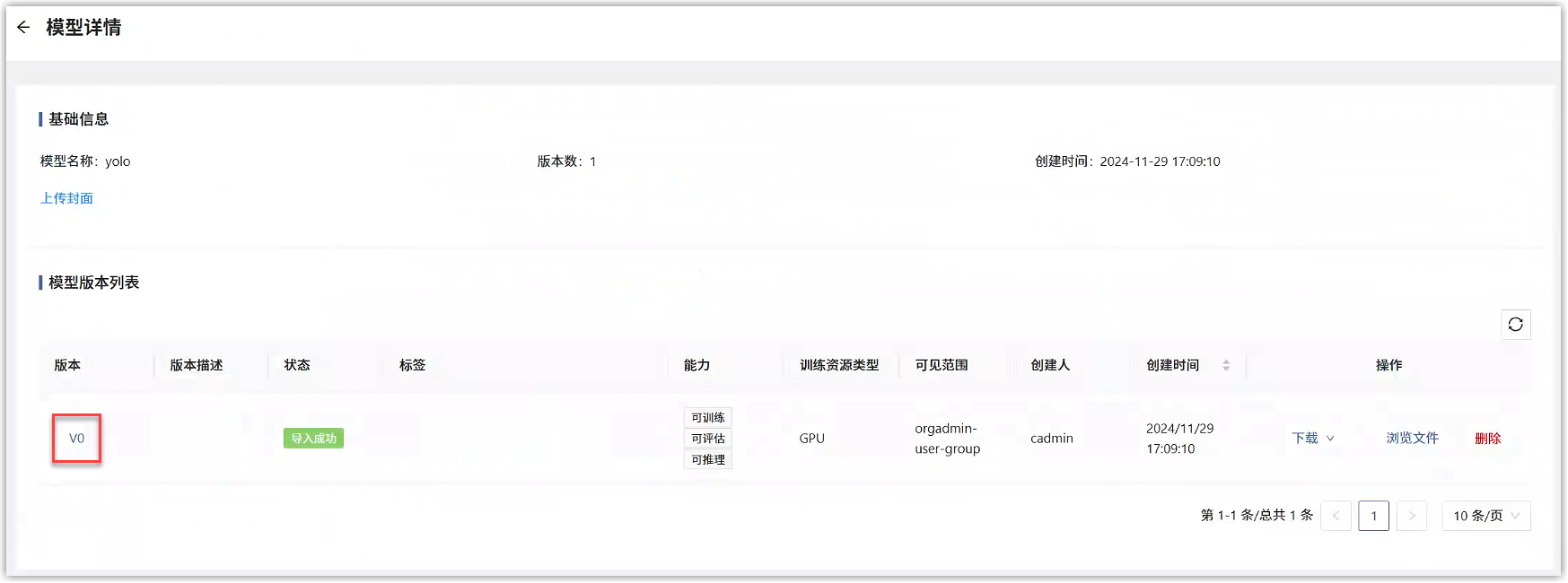
版本详情中,可看到此算法模型的基础信息、训练、评估、压缩、推理配置等,并可进行编辑。
上传模型
您也可以将自己的算法模型上传到平台。用户主页选择“人工智能>模型开发与训练>模型库”,会展开模型库页面,点击“模型上传”按钮。进入创建数据集页面,填写如下信息。
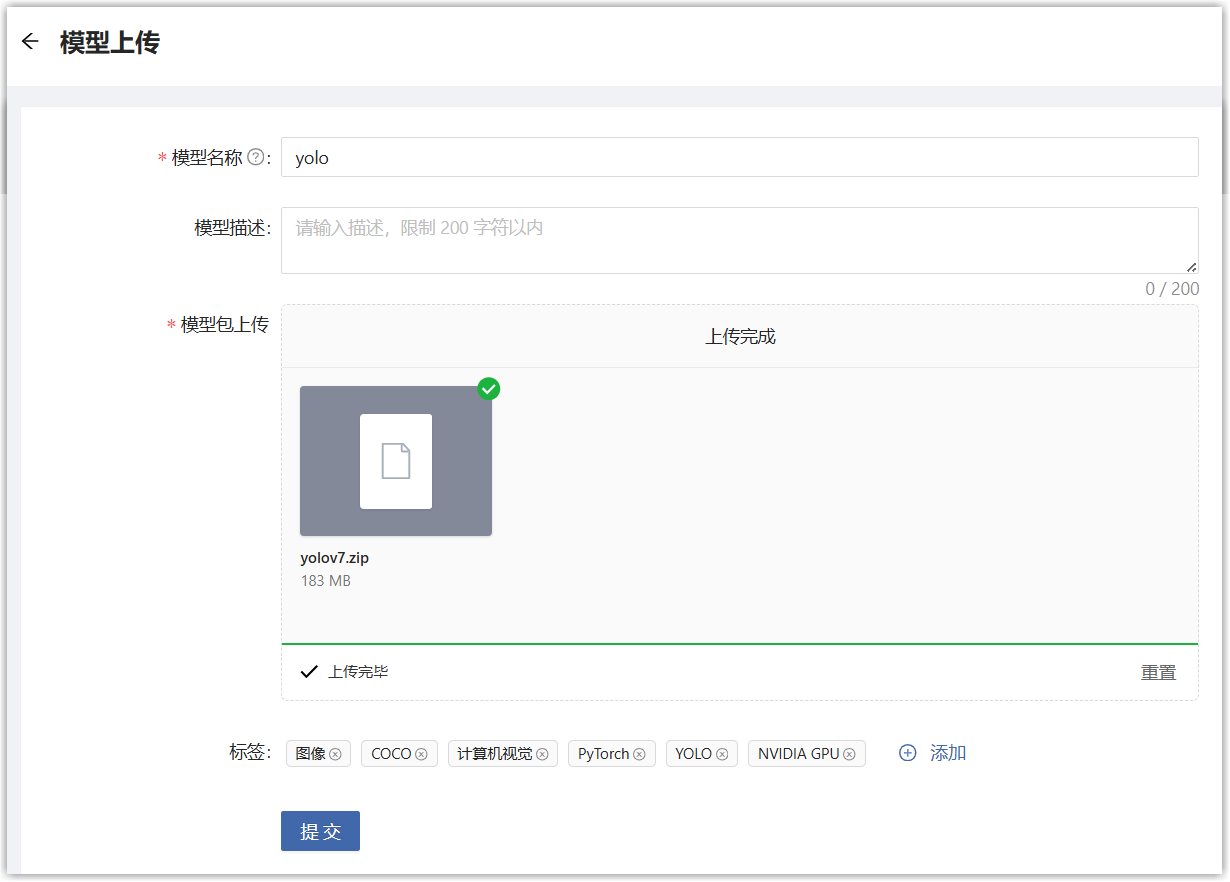
点击提交,即可将模型上传到平台。
适配平台功能
若希望上传的算法模型在平台进行模型训练、模型评估、模型压缩、模型推理,需要对模型进行配置。此处只说明模型训练和模型推理的配置,其他配置类似。
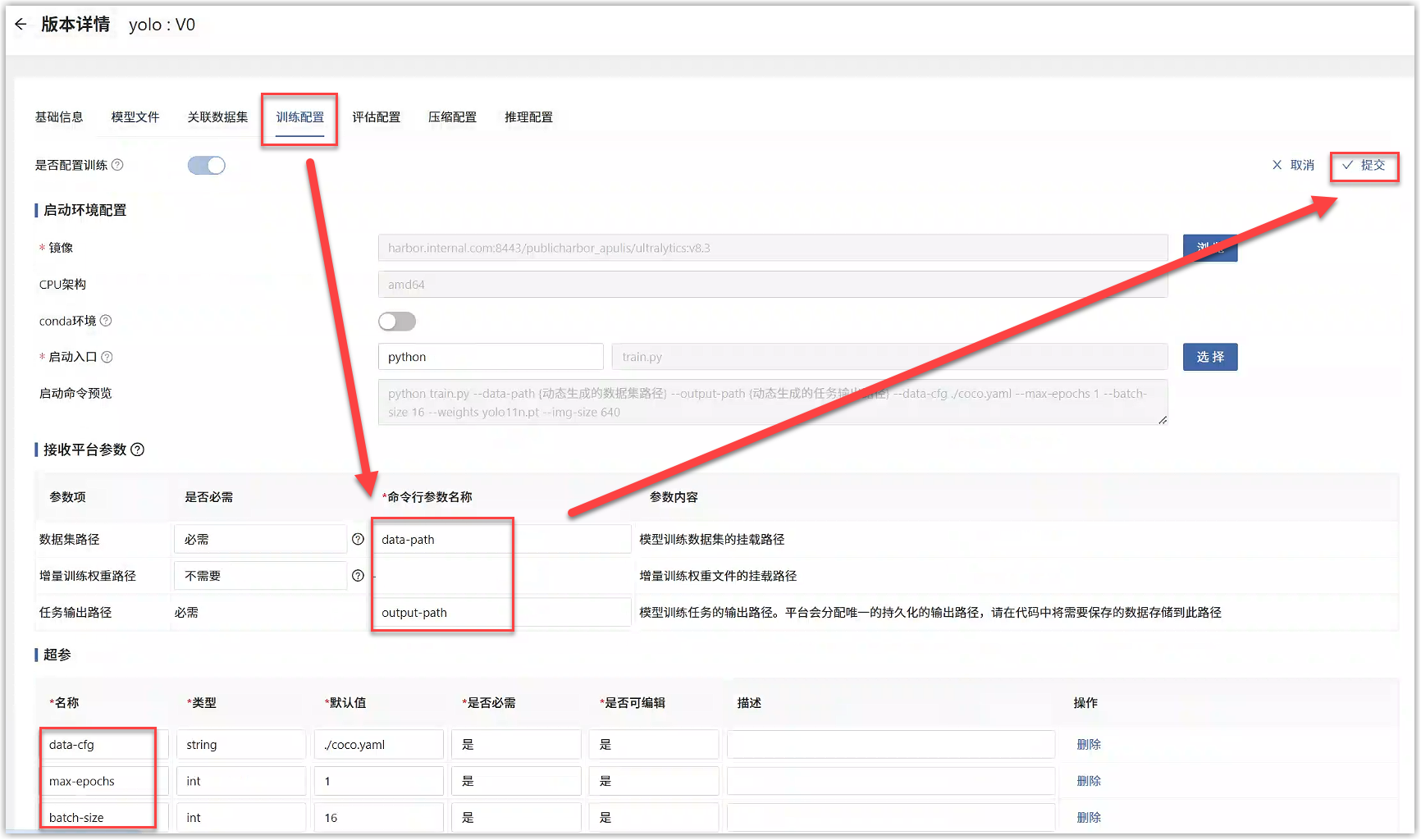
适配平台的模型训练 启动模型训练任务时,平台会动态生成训练数据集路径、训练任务输出路径、增量训练权重路径(下图红框①),并以命令行参数的形式(下图红框②)传递给算法代码的训练启动脚本。此处内容在“模型库”对应的模型版本详情>训练配置中可以查看。
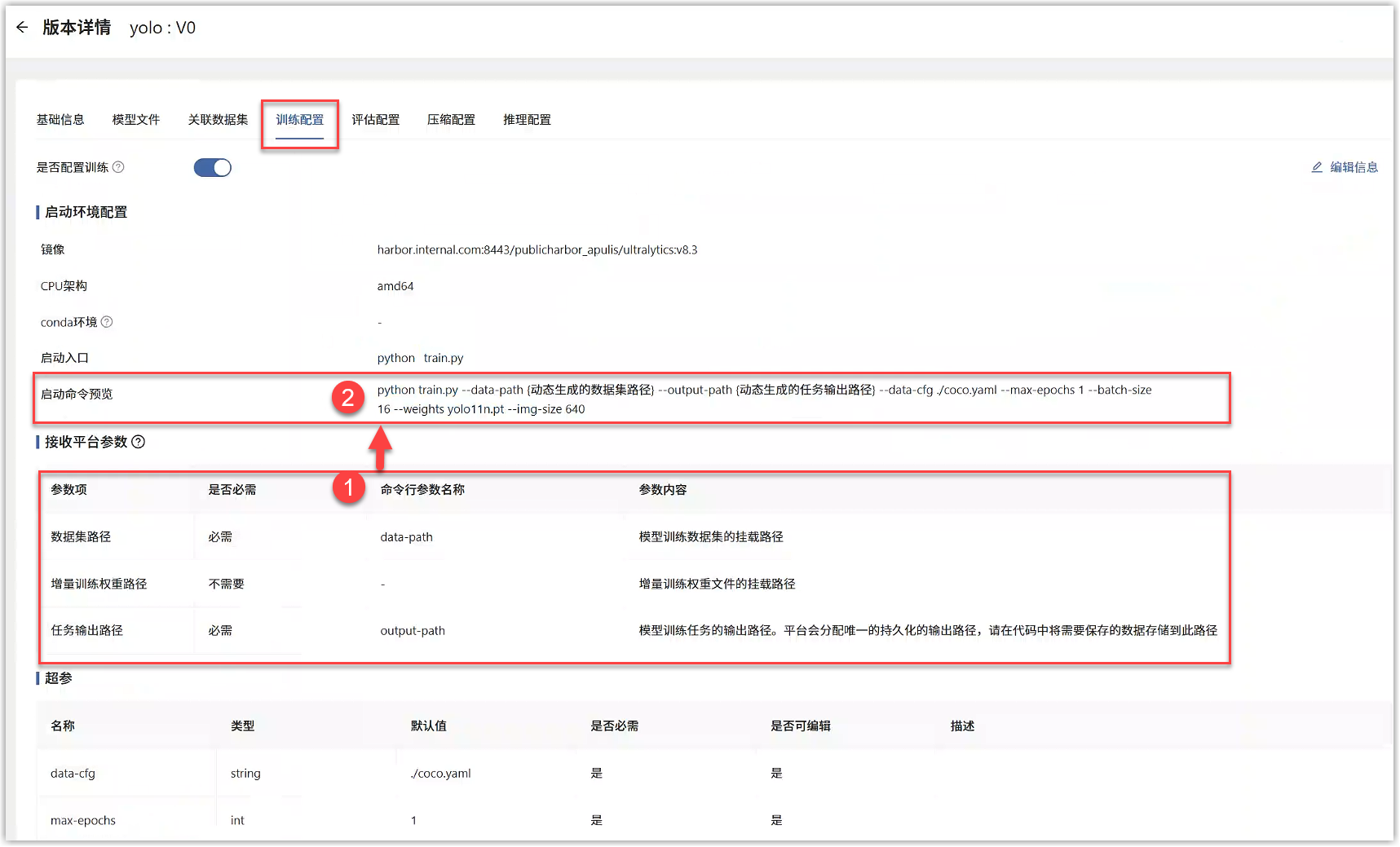
适配需要:
1、 您的算法代码中,支持命令行参数形式接收训练数据集路径、训练任务输出路径、增量训练权重路径。
2、 训练配置的参数名称与代码中的接收参数名称一致。
例如,在本例的YOLO算法代码中,进入模型详情中打开train.py文件,get_args函数中通过命令行的形式接收了平台传递过来的参数,包括数据集路径、输出路径、权重路径和其他超参,如下图所示。点击代码右上角的编辑按钮,可以直接编辑train.py文件,确保接收了上述参数。
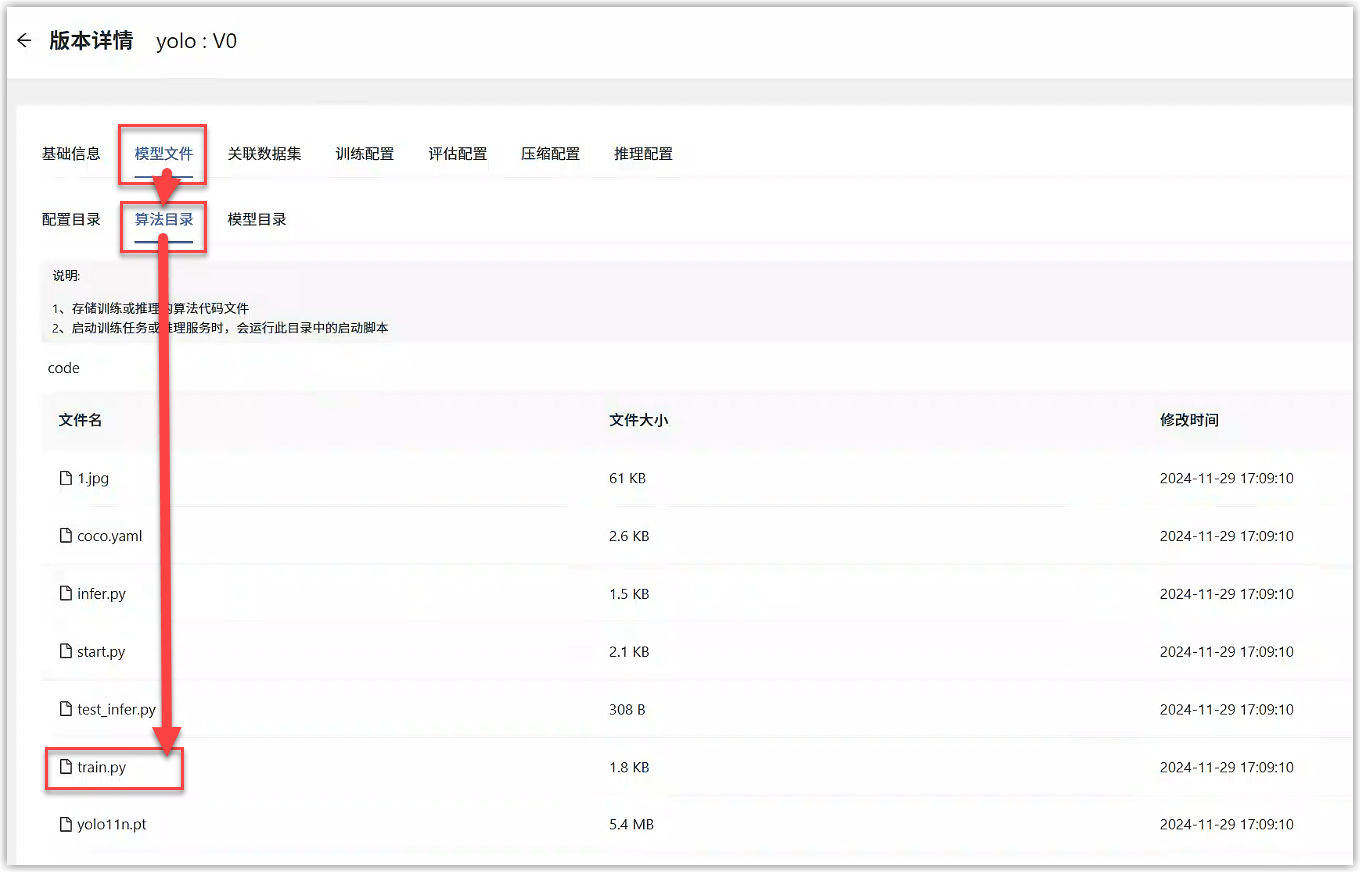
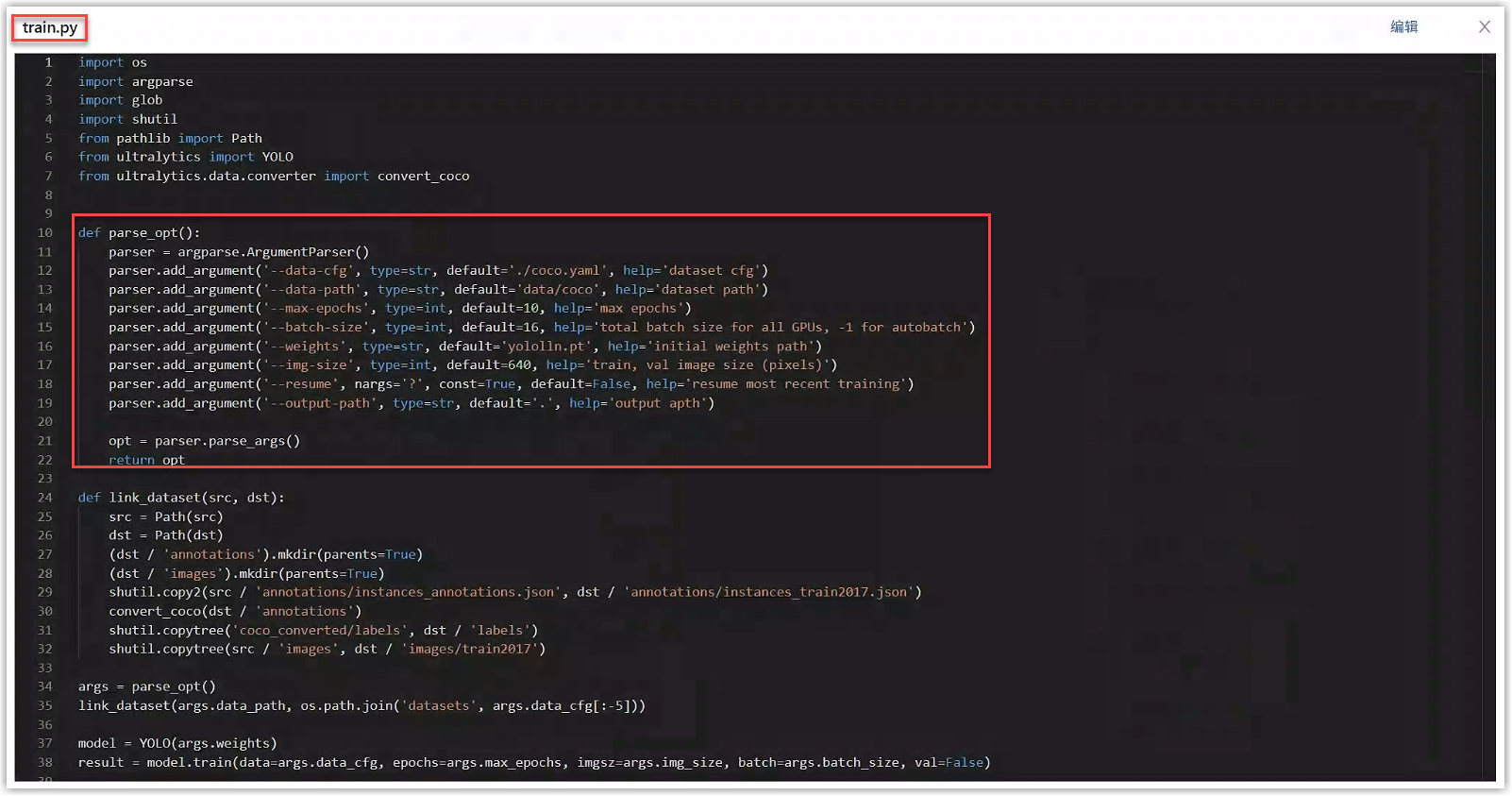
将代码中数据集路径(data-path)、输出路径(output-path)、权重路径(resume)这3个命令行参数名称填写到“模型版本详情>训练配置”的接收平台参数中;将代码中的超参填写到“模型版本详情>训练配置”的超参中,点击提交即可。
对接平台的应用部署
部署在线服务时,平台会动态生成推理模型路径(下图红框①),并以命令行参数的形式(下图红框②)传递给算法代码的推理启动脚本。此处内容在“模型库”对应的模型版本详情>训练配置中可以查看和编辑。需要您的算法代码处理对应的内容并与模型训练配置相匹配。
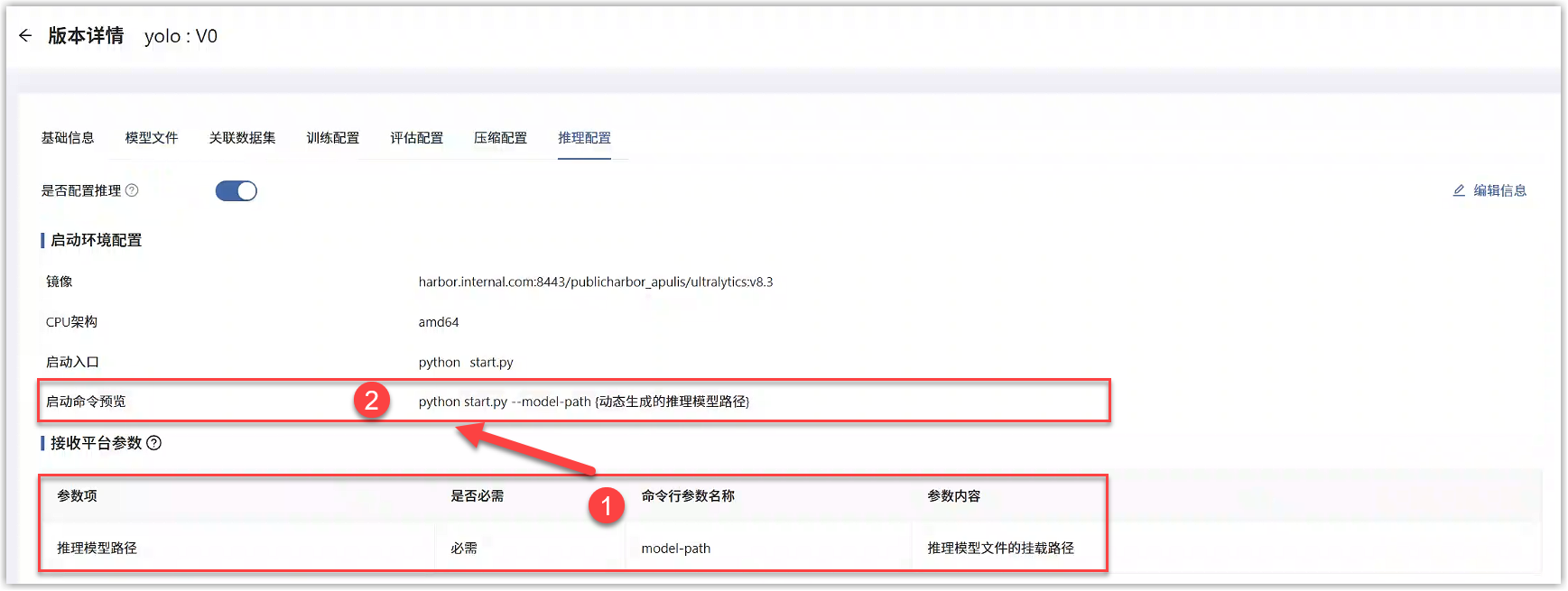
适配需要:
1、 您的算法代码中,支持命令行参数形式接收推理模型路径。
2、 推理配置的参数名称与代码中的接收参数名称一致。
3、 推理配置的推理服务监听端口、访问端点与代码中的一致。
4、 代码的推理协议需要与平台支持的推理协议一致。
例如,在本例的YOLO算法代码中,进入模型详情中打开infer.py文件,get_args函数中通过命令行的形式接收了平台传递过来的参数,包括推理模型路径和其他推理参数,如下图所示。点击代码右上角的编辑按钮,可以直接编辑infer.py文件,确保接收了上述参数。
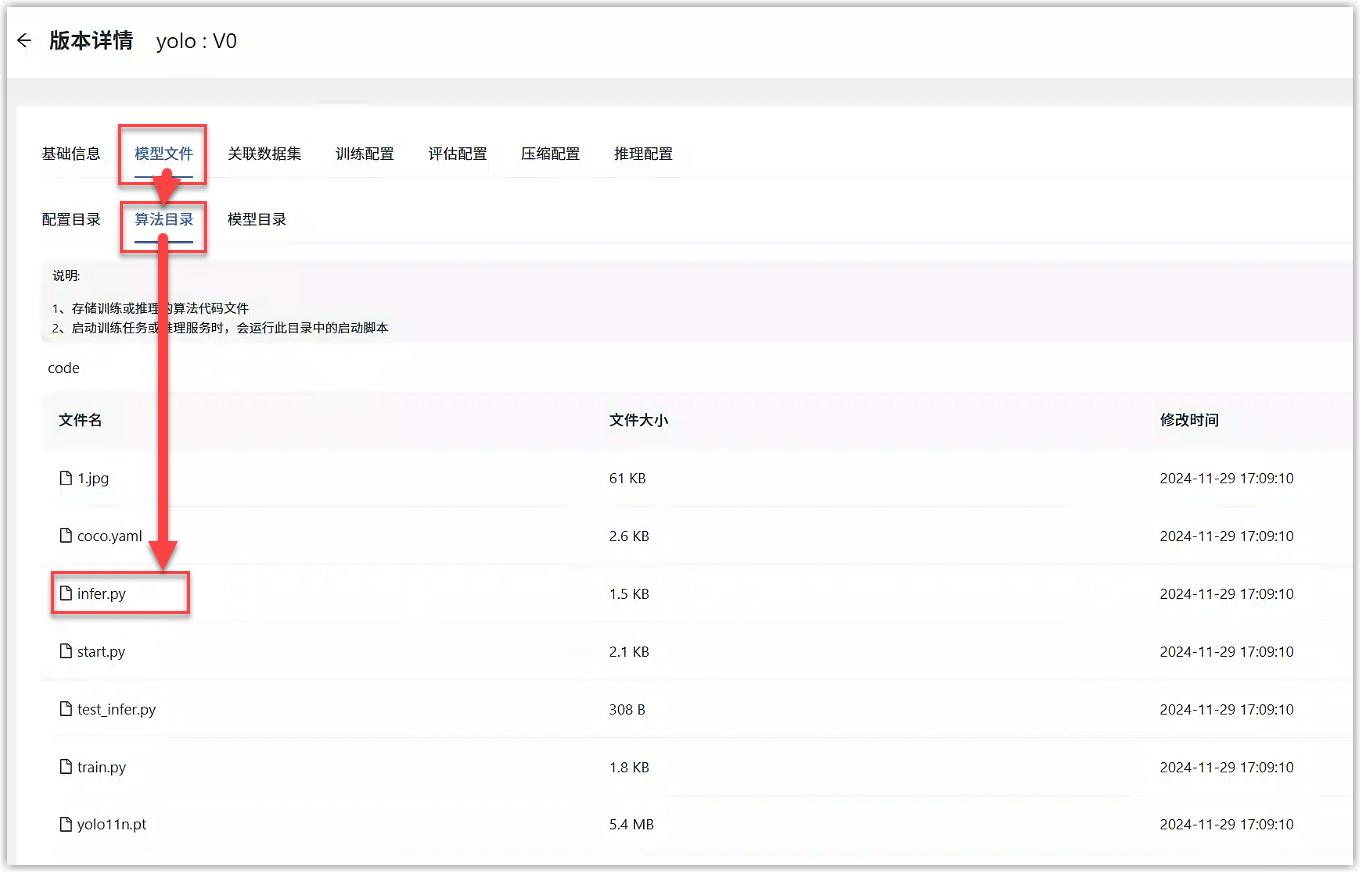
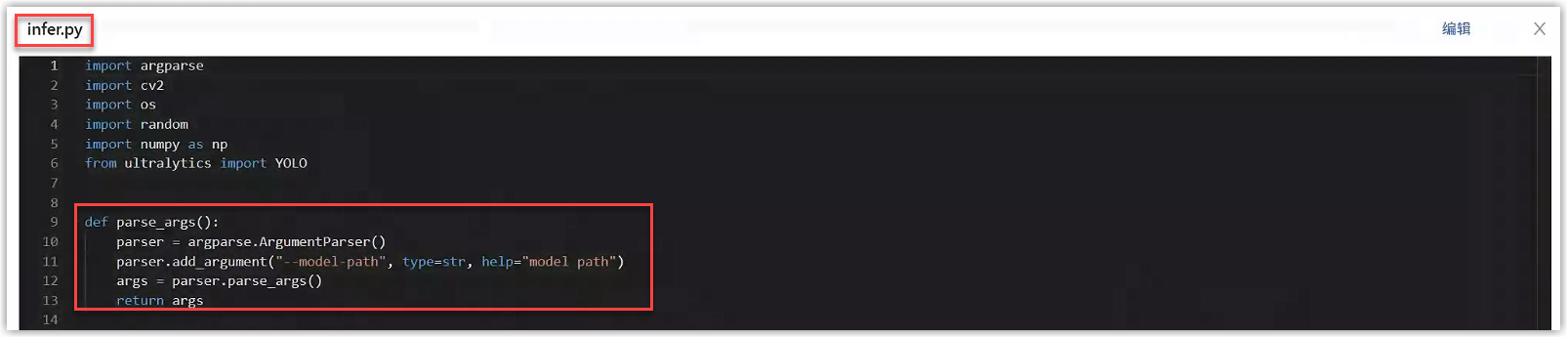
将代码中推理模型路径(model-path)这个命令行参数名称填写到“模型版本详情>推理配置”的接收平台参数中;将代码中的推理参数填写到“模型版本详情>推理配置”的推理参数中,点击提交即可。
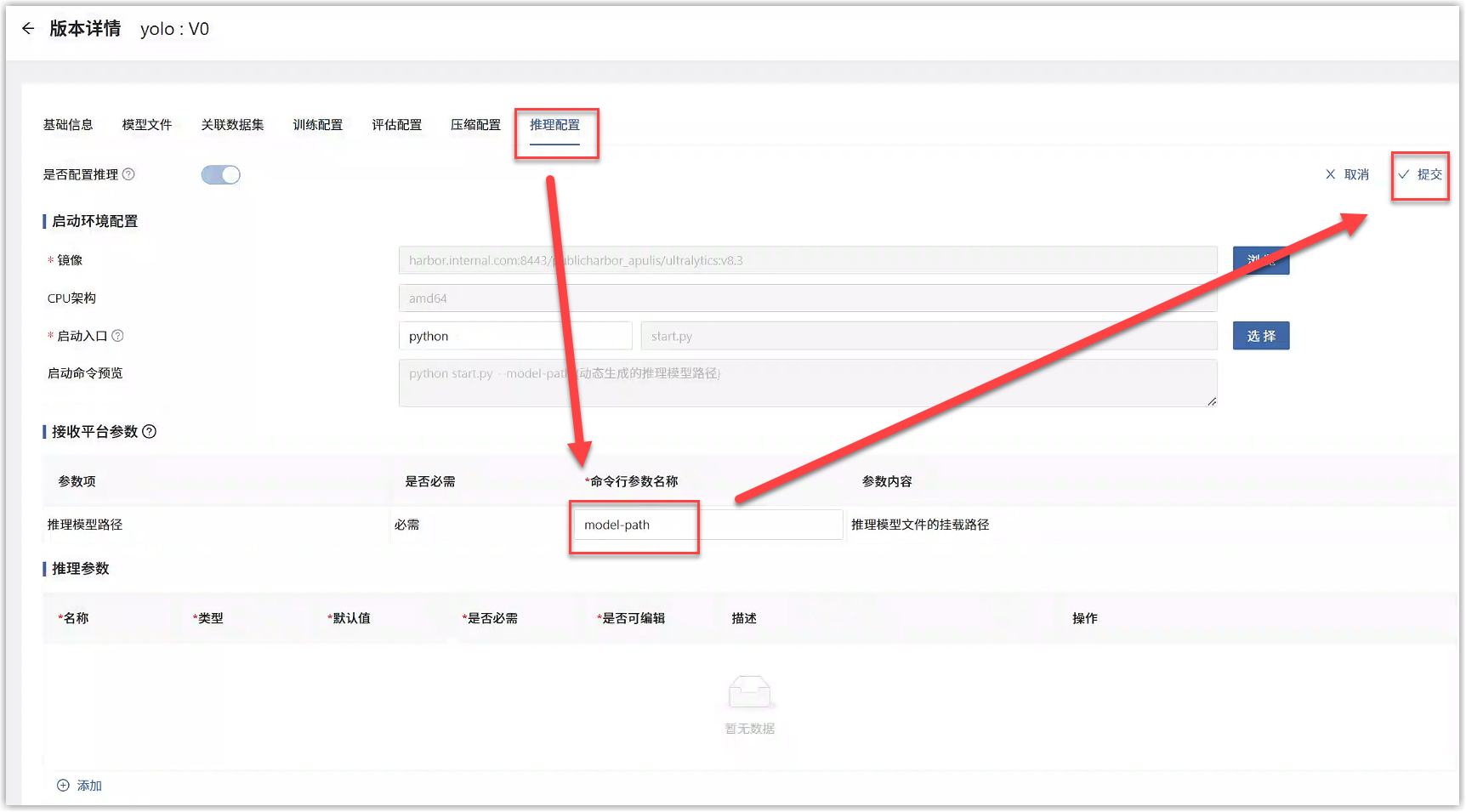
在本例的YOLO算法代码中,进入模型详情中打开start.py文件,@app.post中指定了推理服务访问端点,port中指定了推理服务监听端口,如下图所示。
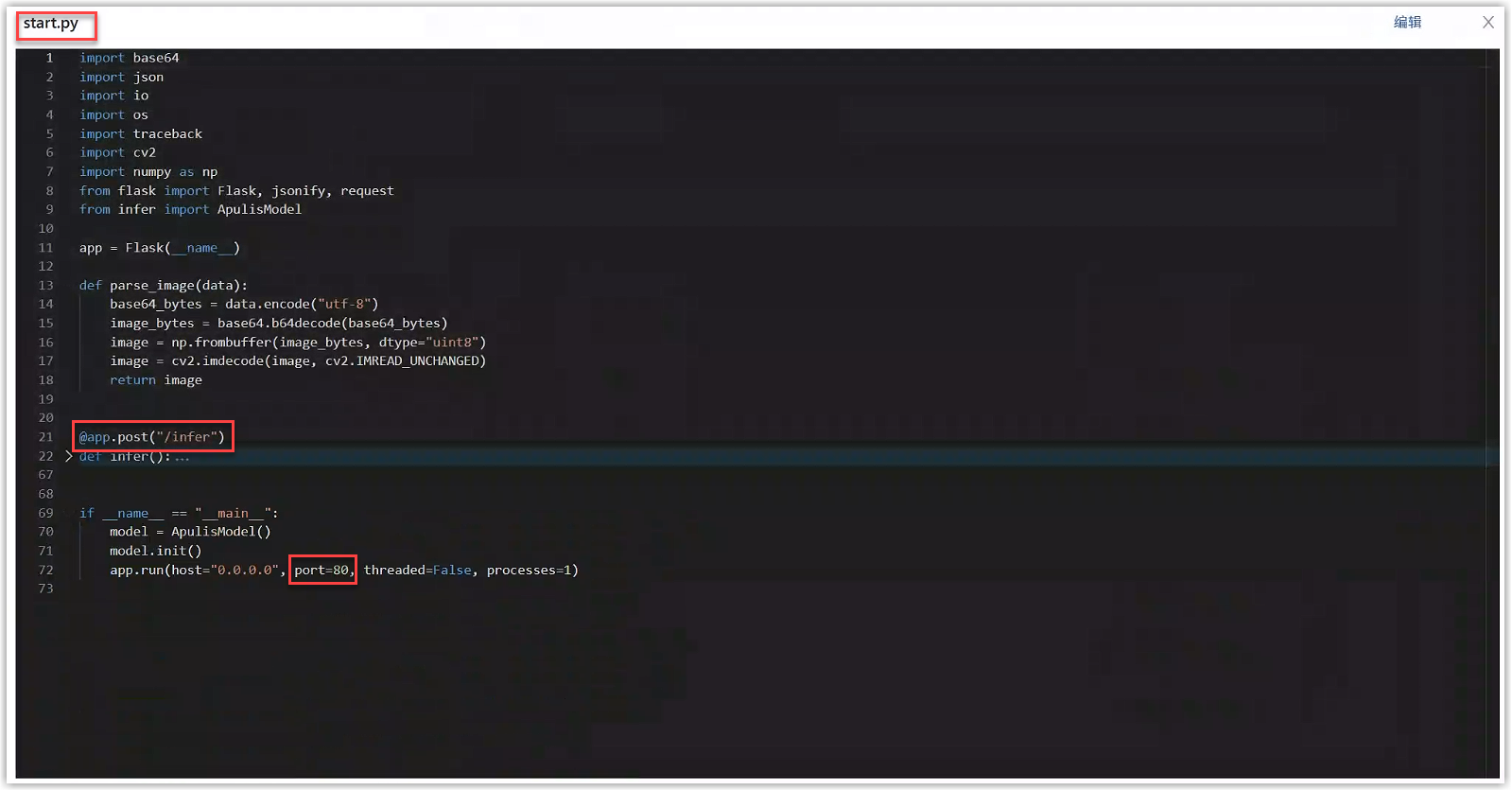
将代码中的访问端点、监听端口填写到“模型版本详情>推理配置”的推理服务信息中,点击提交即可。
平台支持的推理协议详见帮助中心的“编写适配平台功能的推理”章节,算法代码的推理协议需要按其内容进行对接。
2.3 准备镜像
平台运行算法模型,需要运行在镜像中。镜像是一种包含了所有必要软件、库、依赖和配置的打包文件,它为模型提供了一个可移植的、一致的执行环境,确保模型在不同系统或平台上能够无差异地运行。 平台已经预置了本案例中SSD算法的相关镜像,可以直接使用。
| 用途 | 算力资源类型 | 预置镜像名称 | 预置镜像版本 |
|---|---|---|---|
| 运行代码开发环境、模型训练任务 | 英伟达GPU | ultralytics | v8.3 |
3 代码开发
若您希望使用平台纳管的计算资源从0到1开发算法模型,或基于已有算法模型进行修改,可以在代码开发环境中进行开发调试。预置的算法模型无需此步骤。
3.1 启动开发环境
用户主页选择“人工智能>模型开发与训练>代码开发”,会展开开发项目列表页面。在列表页面点击“新建项目”按钮。
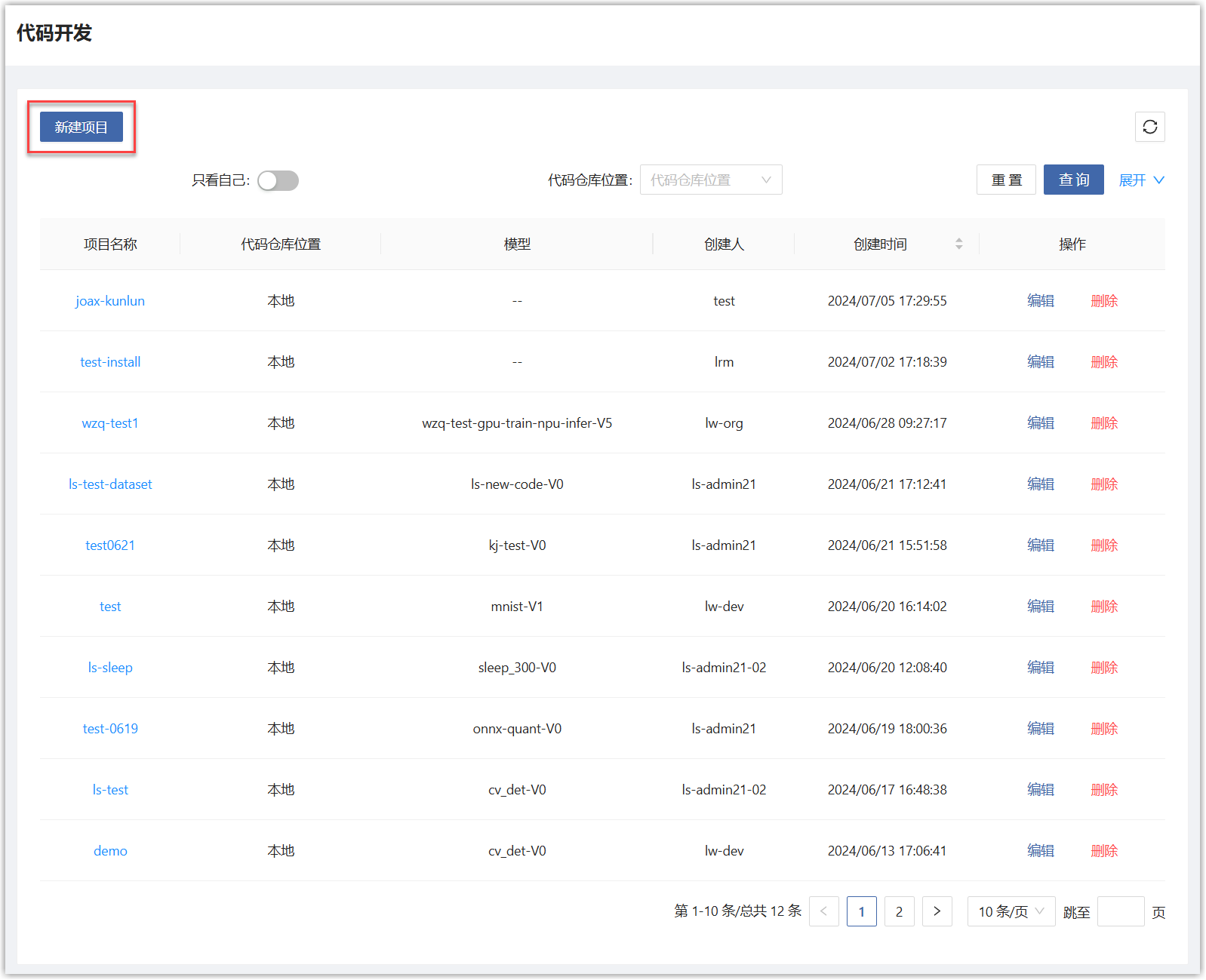
在新建项目弹框中,填写如下信息。
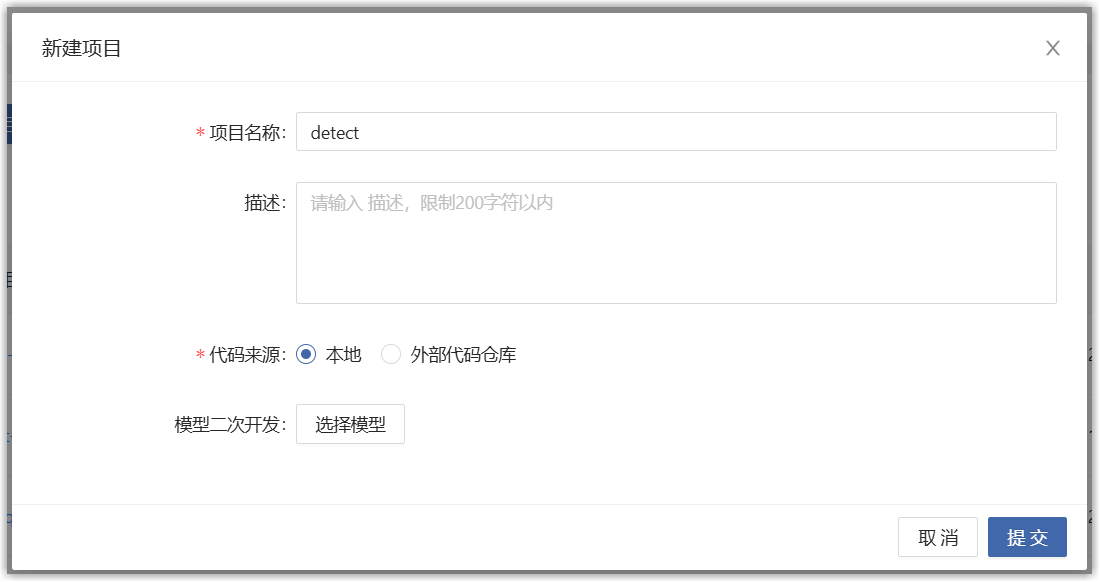
点击“提交”按钮,页面跳转到开发项目列表页面,点击刚才创建的项目名称,进入详情页面,点击“新建开发环境”按钮。
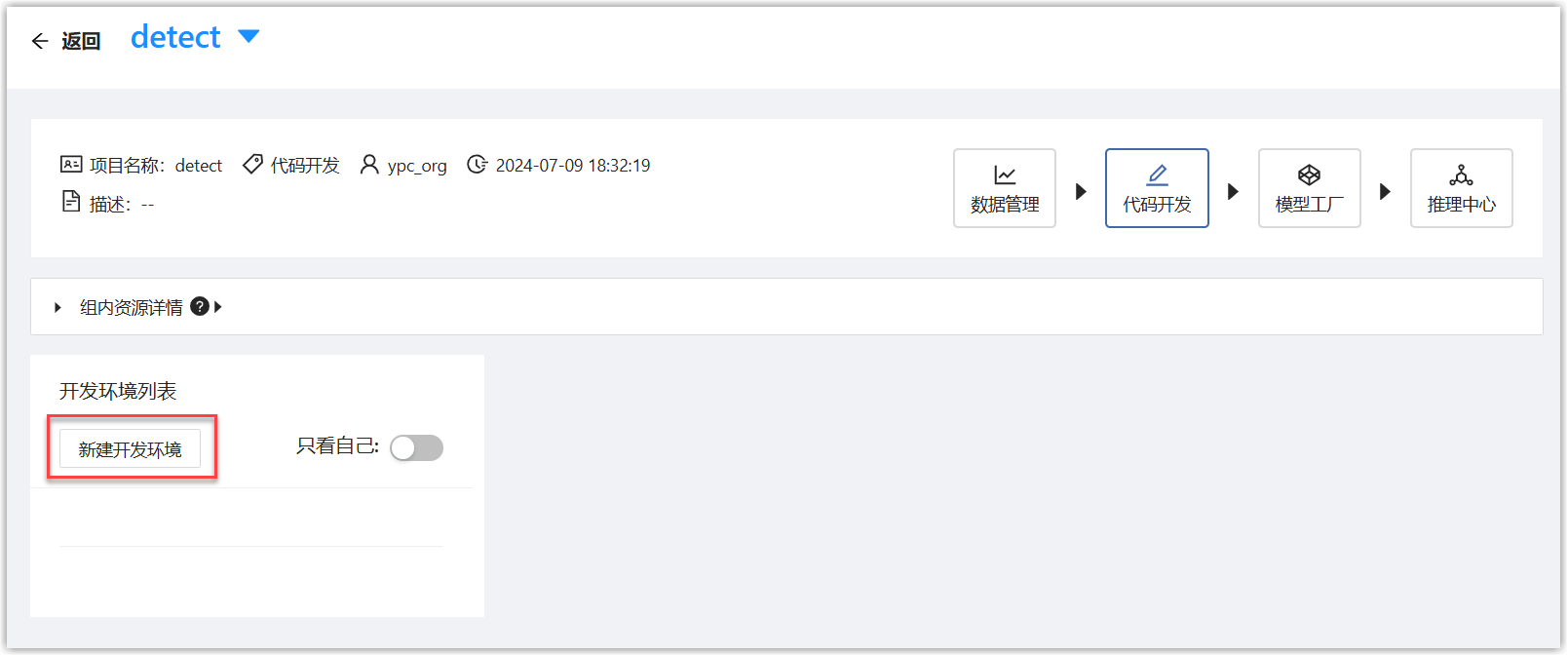
在新建环境页面中,填写如下信息。选择准备好的镜像、数据集,资源选择GPU。
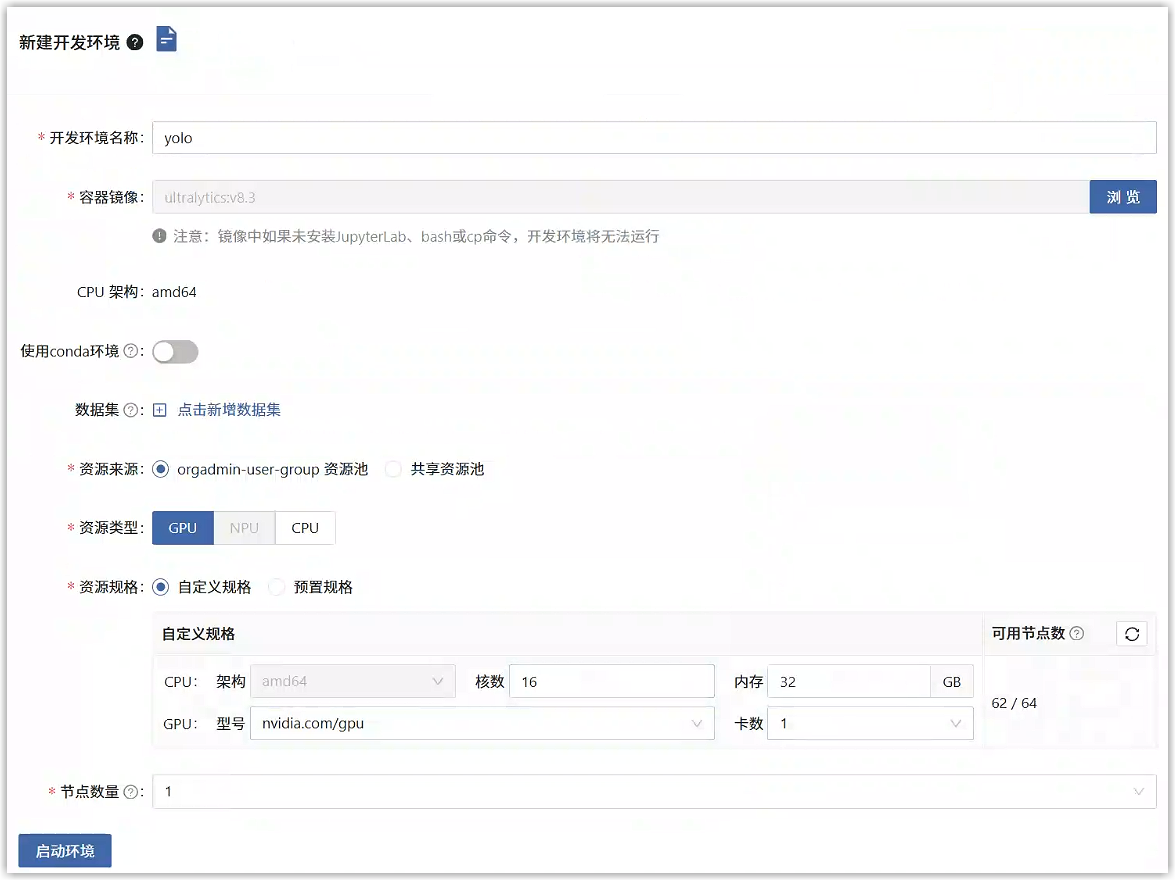
点击“启动环境”按钮,可以看到环境状态为“调度中”,等待状态变为“运行中”,即可使用开发环境。
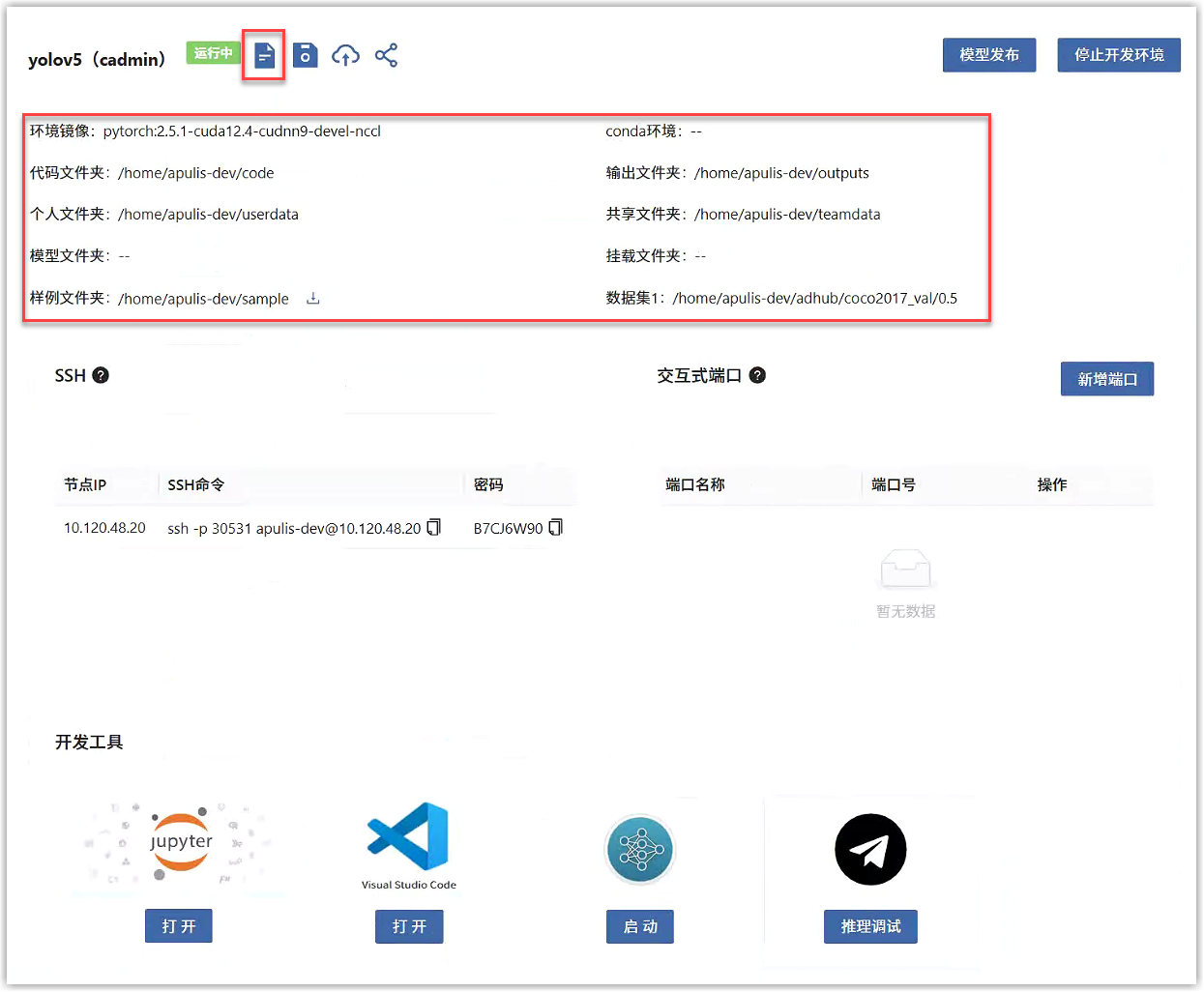
页面中显示了各目录的路径,包括代码、数据集、输出等路径,可以复制使用。点击“查看使用说明”按钮可以查看详细说明,请遵守各目录使用规范。
3.2 调试算法代码
开发环境启动后,在开发工具栏中打开网页版 VSCode。准备好您自己的算法代码,将其算法文件拖拽到VSCode 左侧的code目录中,将其model文件夹中的文件拖拽到VSCode 左侧的outputs目录中,等待上传完毕,即可开始调试代码。
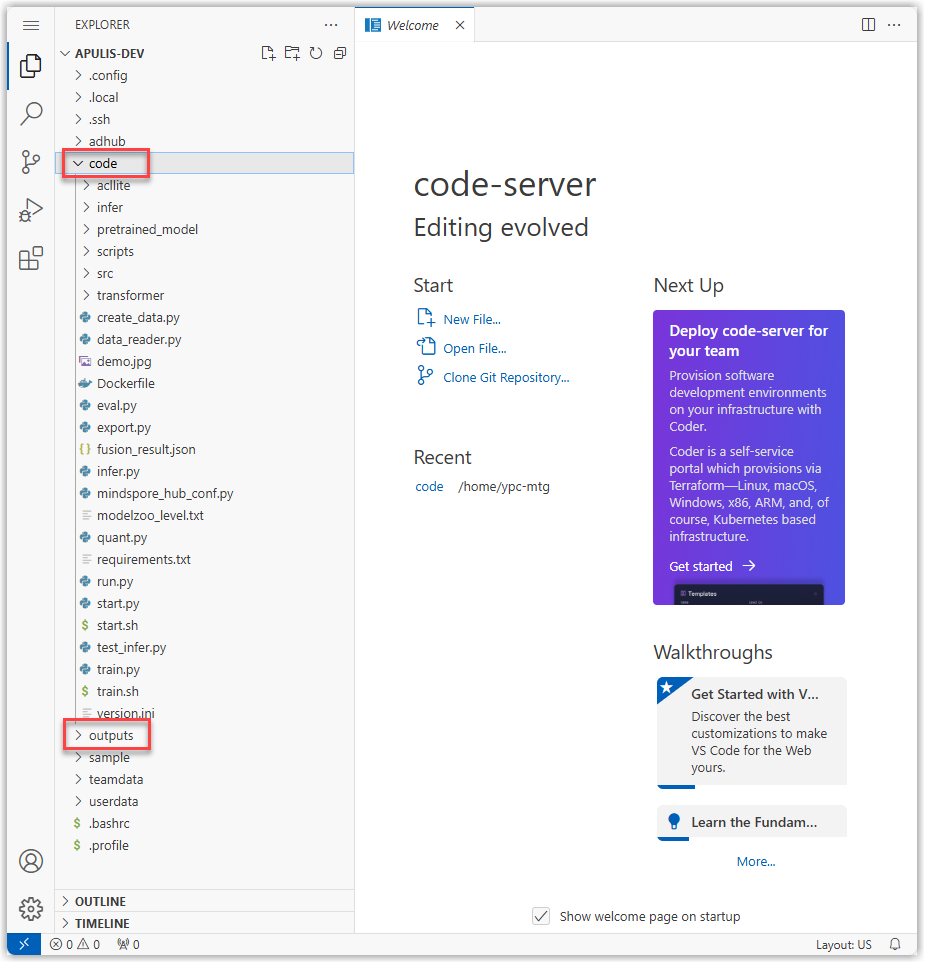
在菜单中打开Terminal,运行代码进行调试。
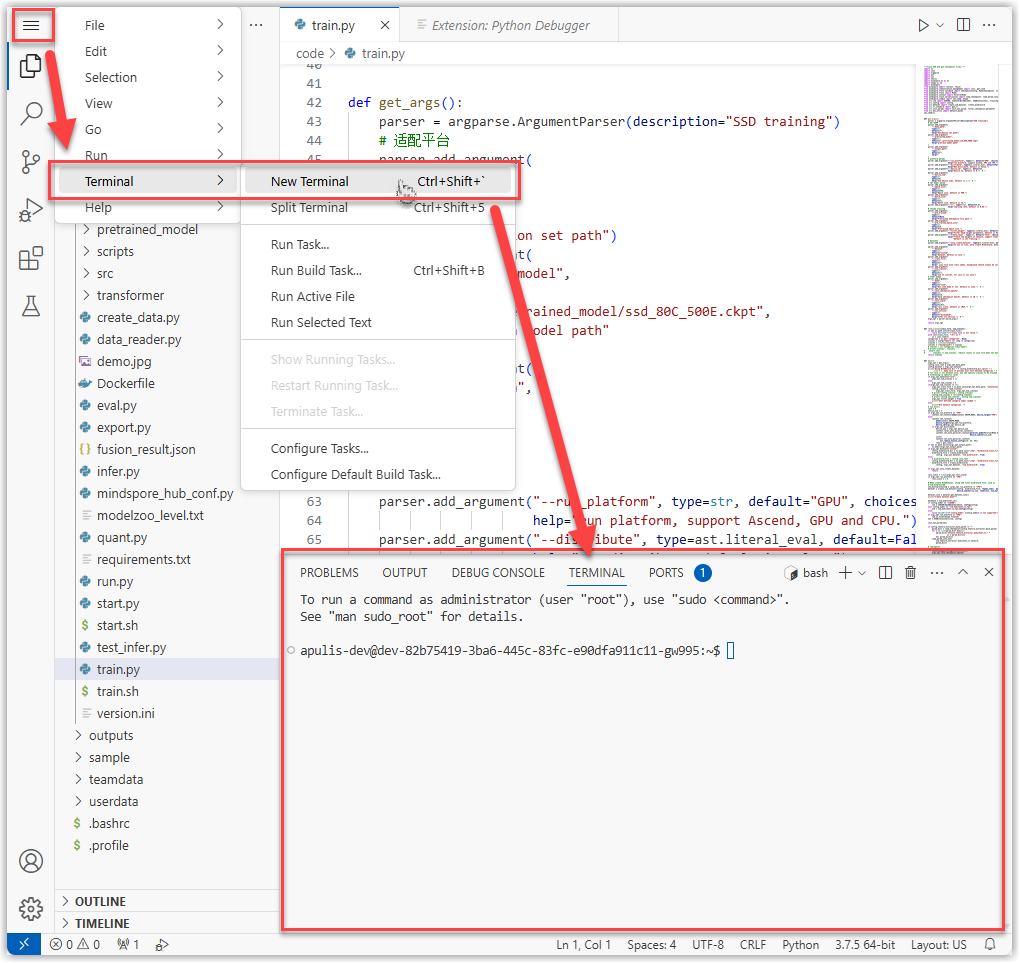
输入您算法模型的训练命令行,调试算法的训练代码,确保能够在代码开发环境中正常训练。
python train.py --data-path /home/aistudio-dev/adhub/coco2017_train/0.1 --output-path /home/aistudio-dev/outputs --data-cfg ./coco.yaml --max-epochs 1 --batch-size 16 --weights yolo11n.pt --img-size 640
输入您算法模型的推理命令行,调试算法的推理代码,确保能够在代码开发环境中正常推理。
python start.py --model-path /home/aistudio-dev/outputs
若希望推理代码能够提供在线服务,需要编写对应的推理服务框架。在开发环境的sample目录中,提供了模板和案例,详见其中的README文档。
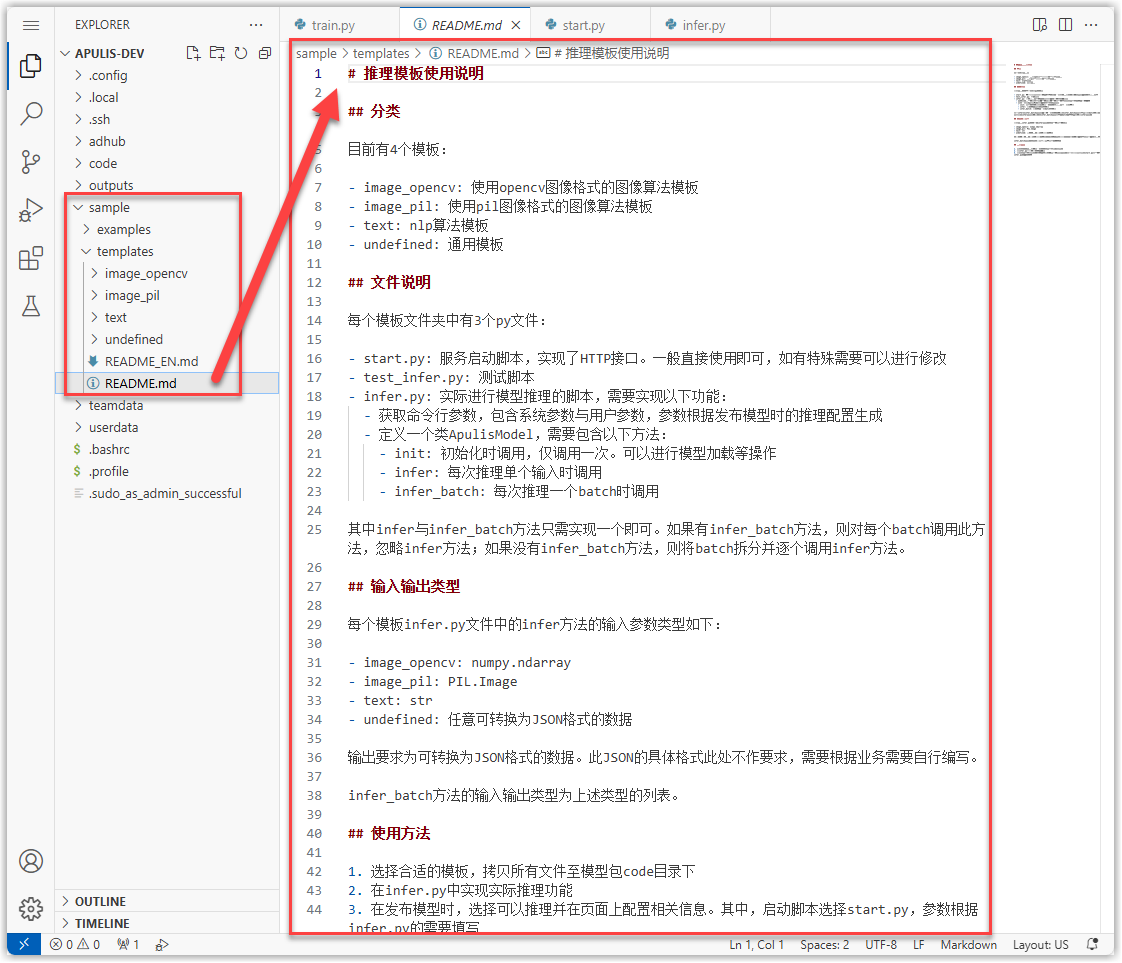 在本例YOLO算法代码中,已编写好了推理服务框架,无需调试,可以直接使用。
在本例YOLO算法代码中,已编写好了推理服务框架,无需调试,可以直接使用。
3.3 对接平台功能
若希望算法模型在平台进行模型训练、模型评估、模型推理,需要在代码中对接平台参数。
- 对接模型训练:需要您的算法代码支持命令行参数形式接收训练数据集路径、训练任务输出路径、增量训练权重路径。
- 对接模型评估:需要您的算法代码支持命令行参数形式接收评估数据集路径、评估任务输出路径、模型权重路径。
- 对接应用部署:需要您的算法代码支持命令行参数形式接收推理模型路径,推理接口协议与平台协议对接。
具体对接方法可参考上文“准备算法代码”章节。
3.4 发布到模型库
当算法代码调试完毕后,可以将其发布到模型库,进行训练、评估、和推理。注意,若代码开发环境安装了模型运行依赖的新的软件包,请先保存镜像再发布模型,否则模型可能无法正常运行。
在开发环境中,点击“模型发布”按钮,进行发布。

在模型发布页面中,本案例配置模型的基础信息、训练配置、和推理配置。
- 基础信息:选择要发布的内容和标签。
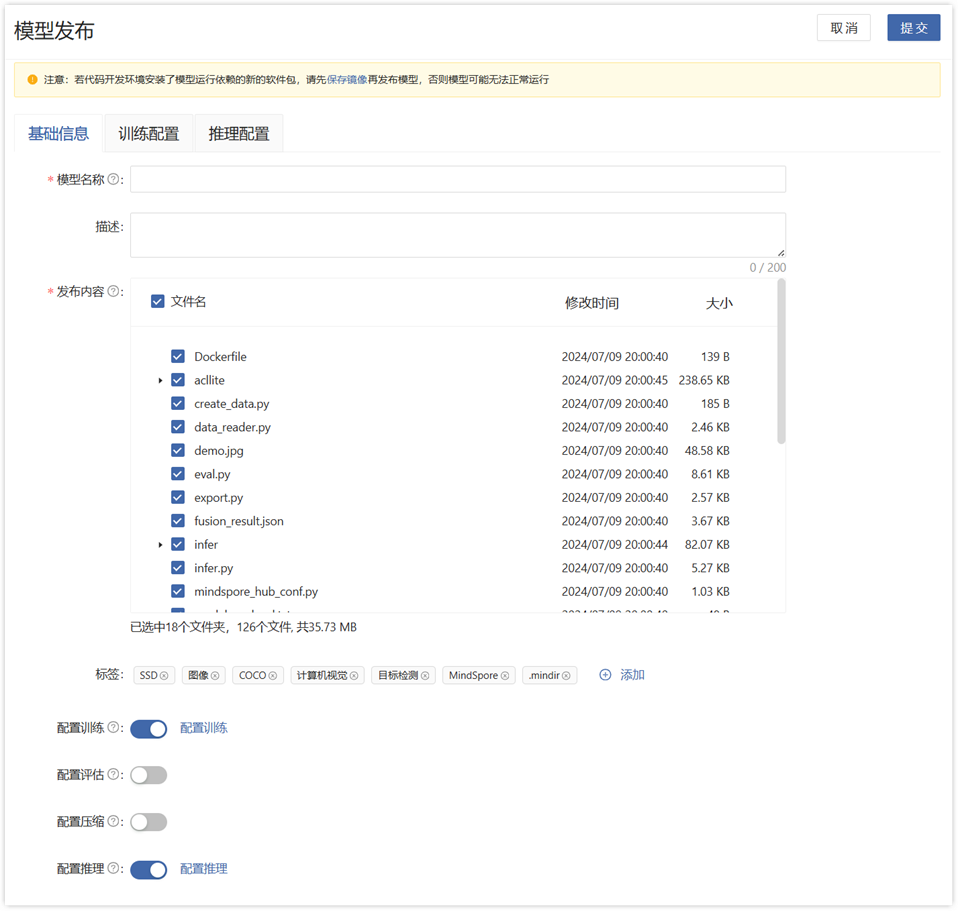
- 训练配置:选择启动命令的启动脚本
train.sh,“代码接收的命令行参数名称”需要与代码实际接收的名称一致,否则会出错,超参填写代码能够处理支持的参数,填写后就能预览启动命令了。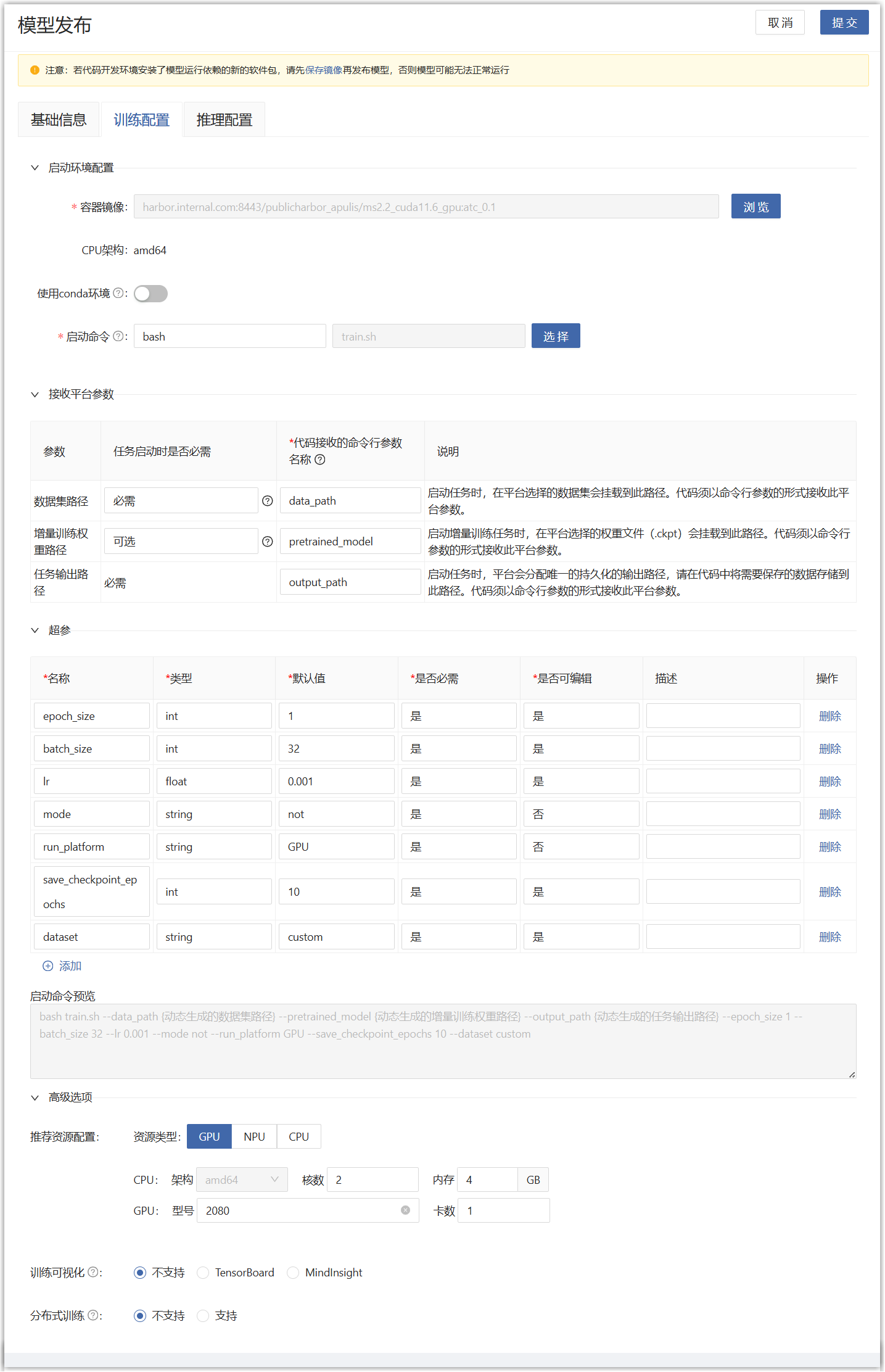
- 推理配置:选择启动命令的启动脚本
start.sh,“代码接收的命令行参数名称”需要与代码实际接收的名称一致,推理参数填写代码能够处理支持的参数,填写后就能预览启动命令了。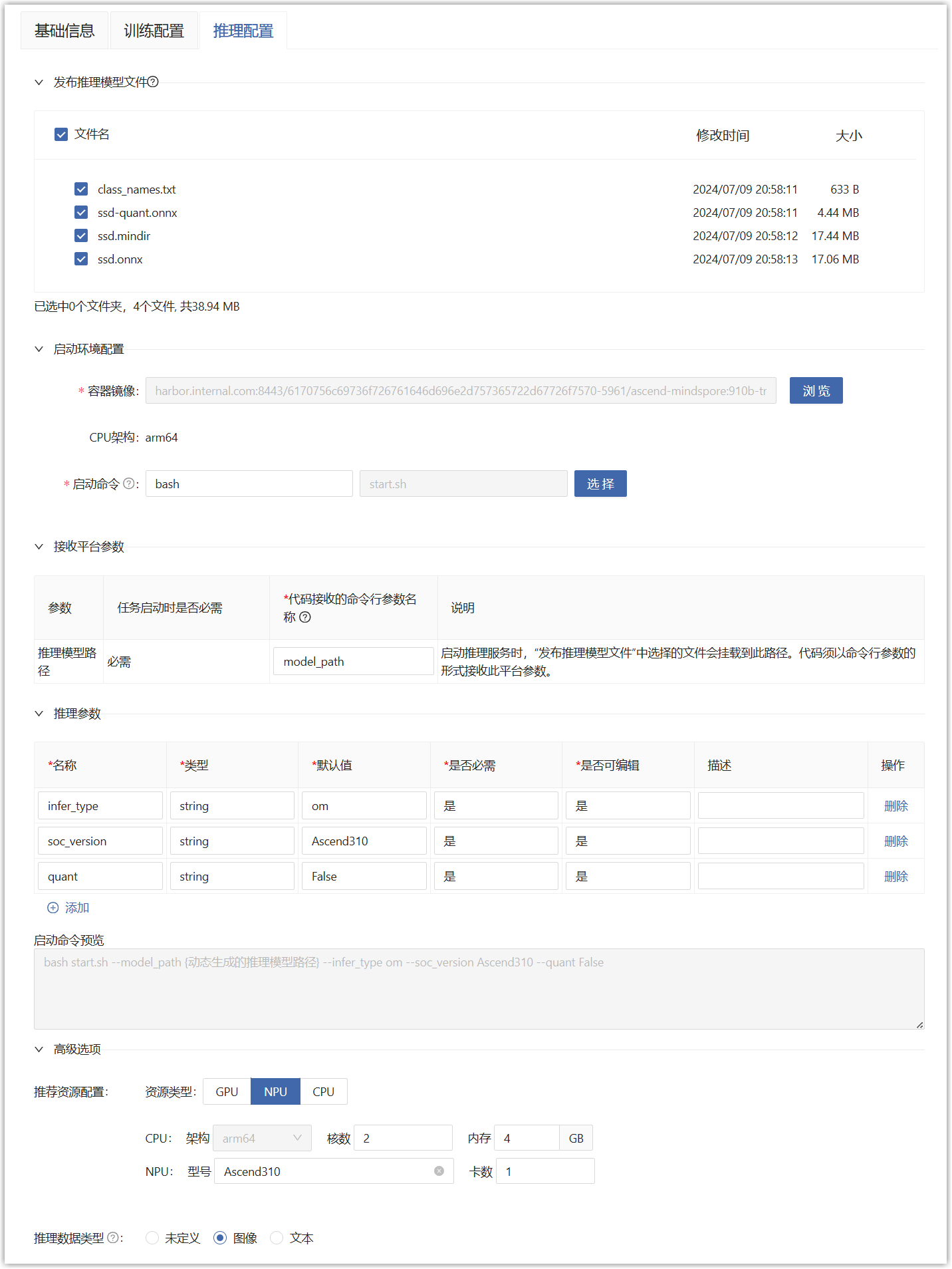
配置好后,点击“提交”按钮,页面跳转到模型库的版本详情页面,可以看到自动新建了一个版本,状态为“导入中”,等待状态变为“导入成功”后,即完成了模型发布。
-9fa915f1b6166b0aeafc9e4adf5bf050.png)
4 模型训练
在开发环境中调试好的算法模型,还需要进行大数据量的训练,来优化模型参数,使其能够准确预测和识别新数据。
4.1 创建训练任务
用户主页选择“人工智能>模型开发与训练>模型训练”,会展开训练项目列表页面。在列表页面点击“新建项目”按钮。
在新建项目弹框中,填写如下信息。
点击“提交”按钮,页面跳转到训练项目列表页面,点击刚才创建的项目名称,进入详情页面,点击“新建任务”按钮。
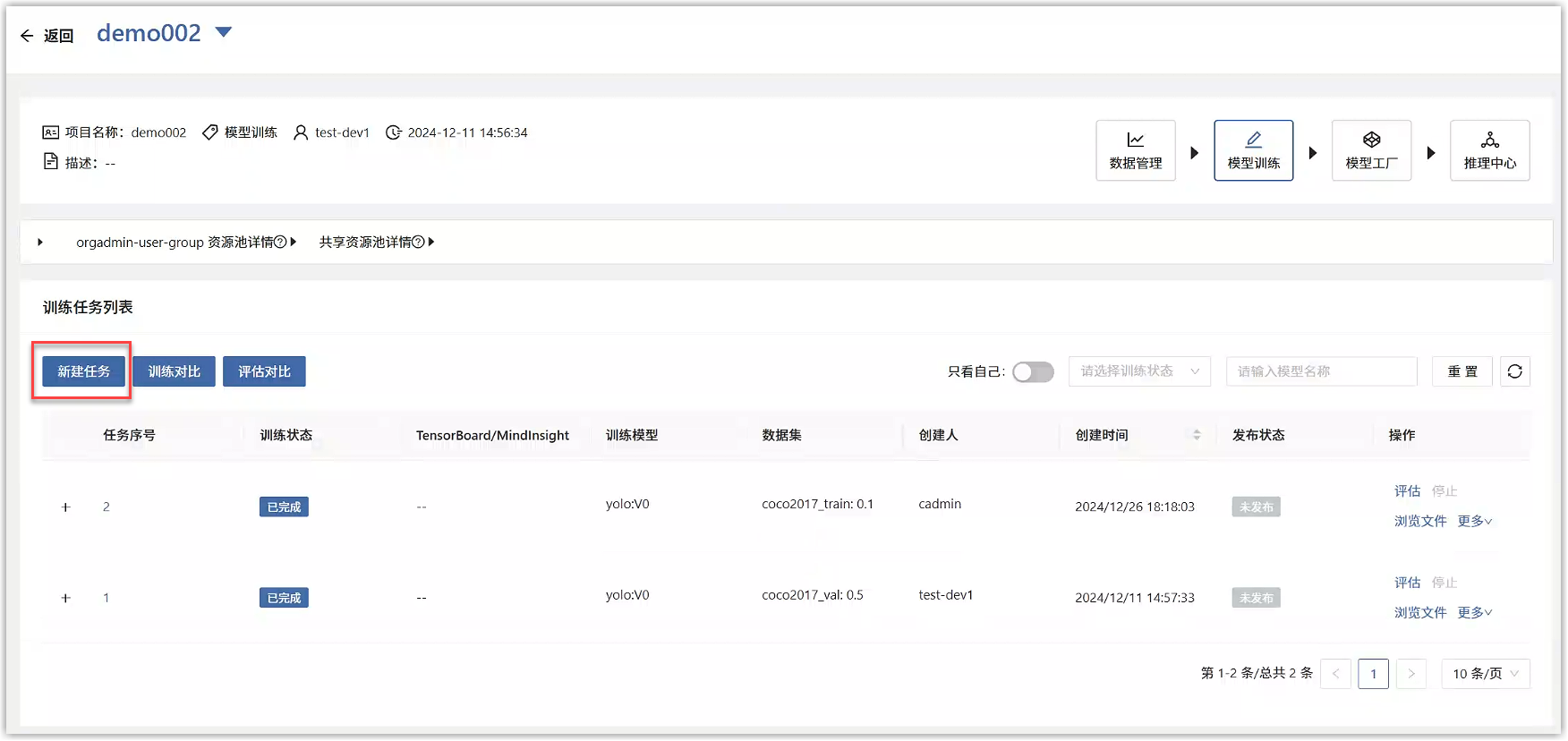
在新建模型训练任务页面中,填写如下信息。选择刚才发布的模型、准备好的训练数据集,超参数根据情况调整,训练资源选择GPU,注意内存需要根据数据集的大小调整,否则训练过程会报错,此处建议16GB。
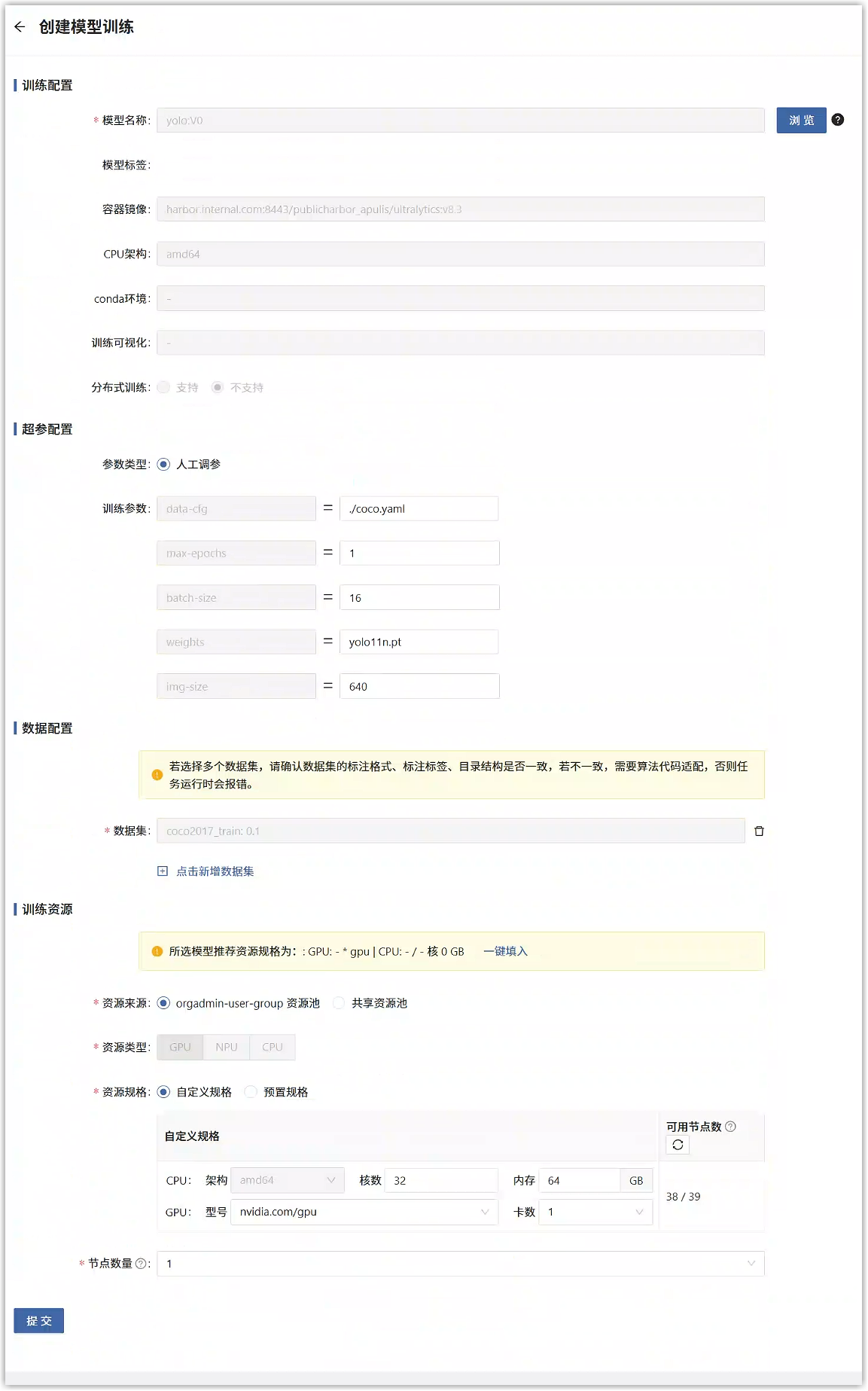
点击“提交”按钮,页面跳转到训练任务列表页面,点击刚才创建的任务编号,进入详情页面可以看到任务状态为“运行中”,点击“日志信息”,在自动刷新。
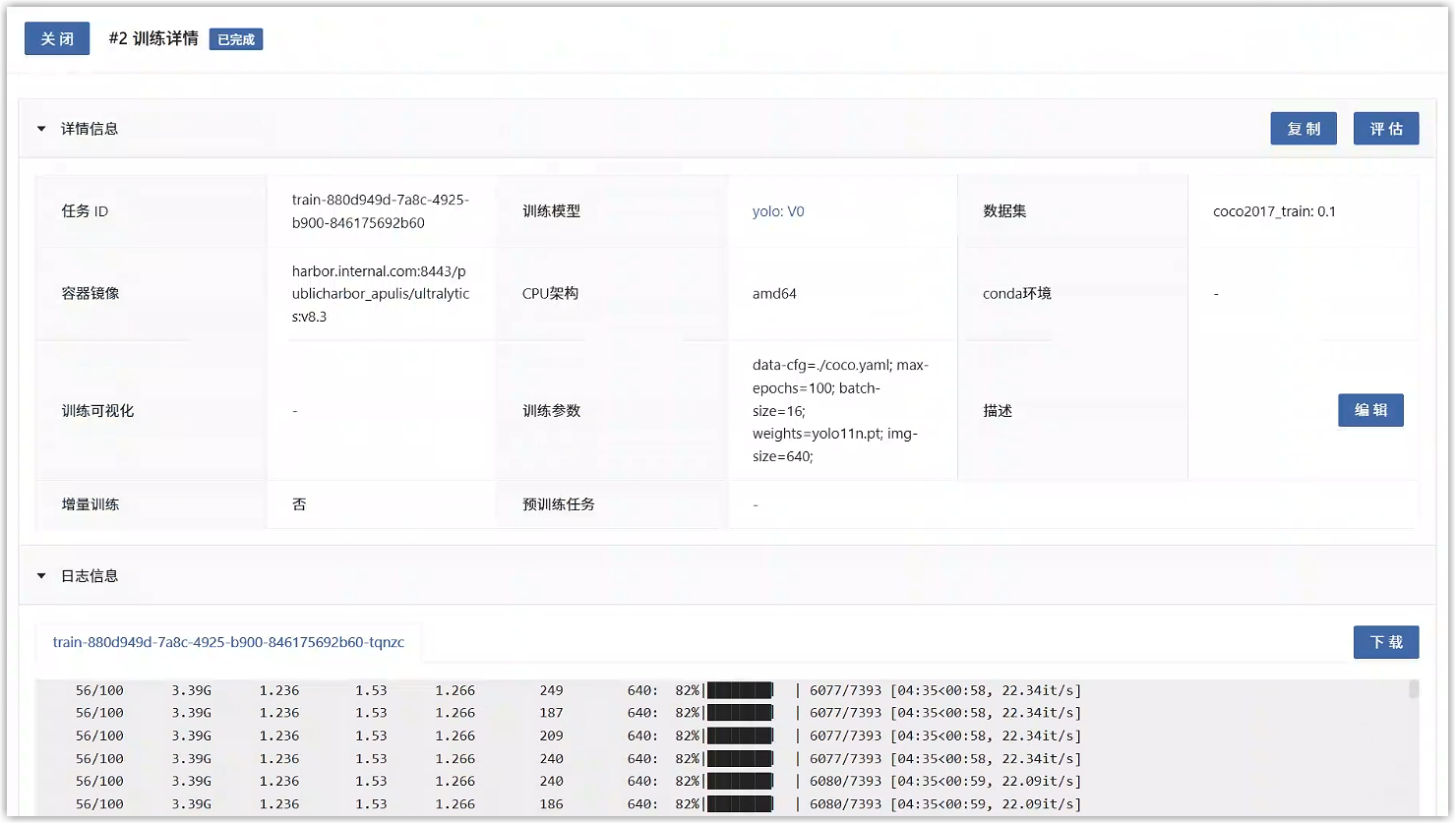
等到任务状态变为“已完成”时,即完成了此次训练。在任务列表中,点击“浏览文件”,可以浏览任务输出文件。
4.2 发布训练后模型到模型库
模型训练或评估后,可以将训练输出的内容发布为新版本。
项目详情页面中,对于已经训练完成的任务,点击“更多-发布”按钮,进入发布页面。
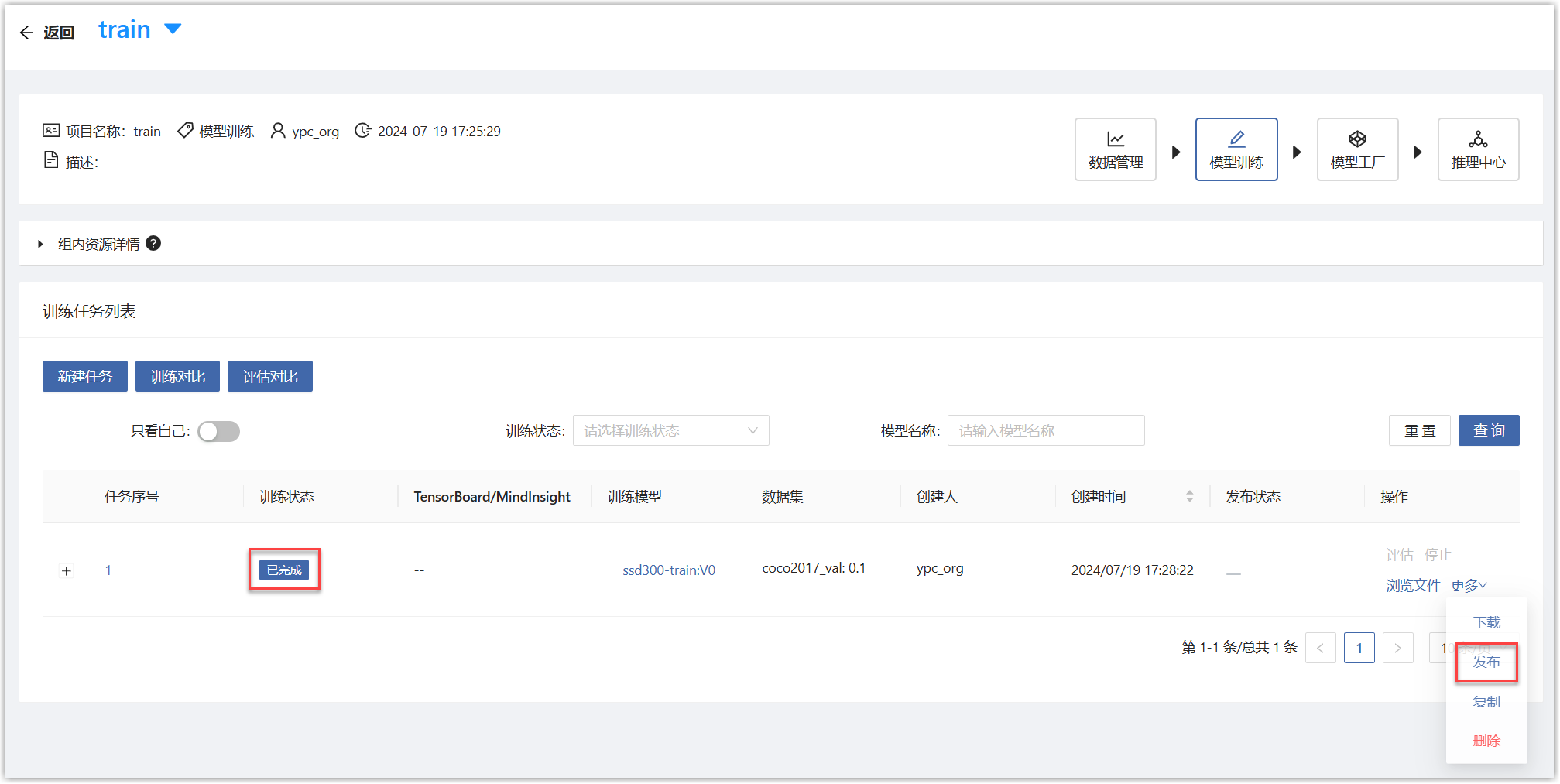
在发布页面,填写如下参数。
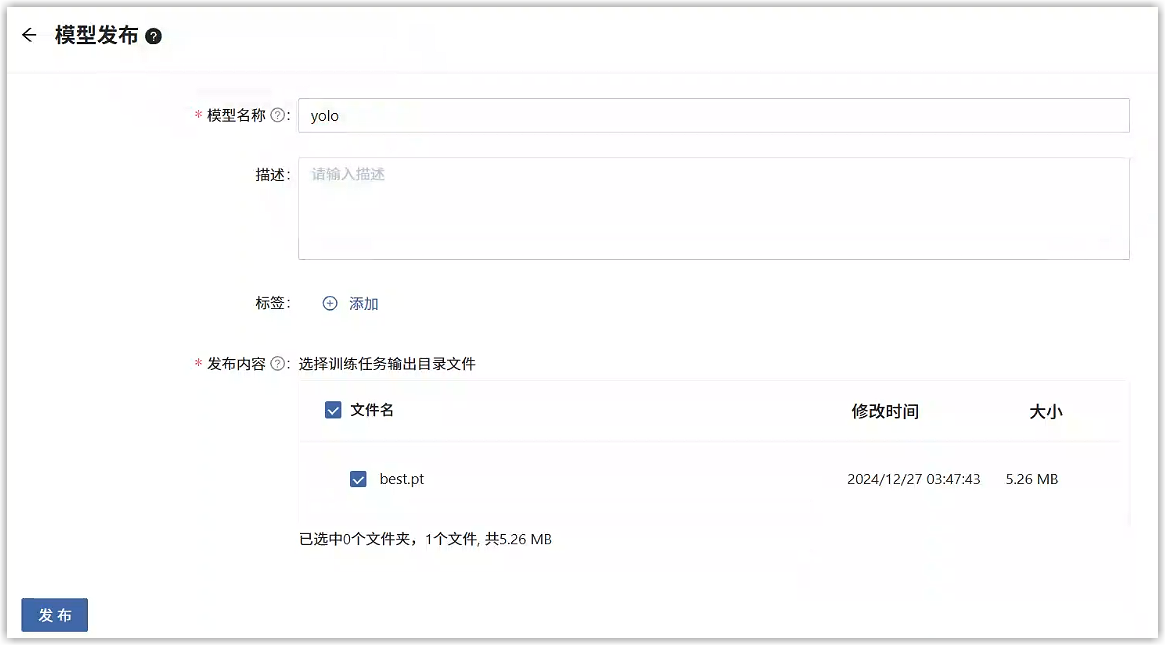
填写完毕后点击发布按钮,即会按照上述信息将模型发布到模型库。在训练任务列表中,能看到此次发布的状态。
5 应用部署
将训练好的模型部署为在线服务服务。用户主页选择“人工智能>中心部署>在线服务”,会展在线服务列表页面。在列表页面点击“部署服务”按钮。
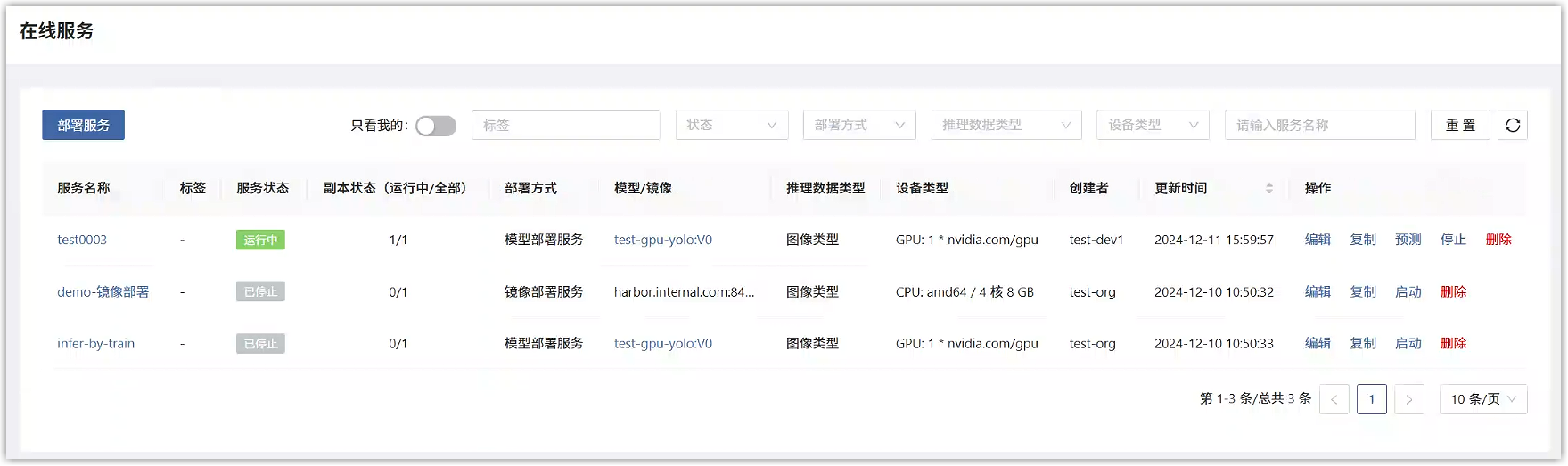
在创建页面中,填写如下参数,选择刚才发布的模型版本。
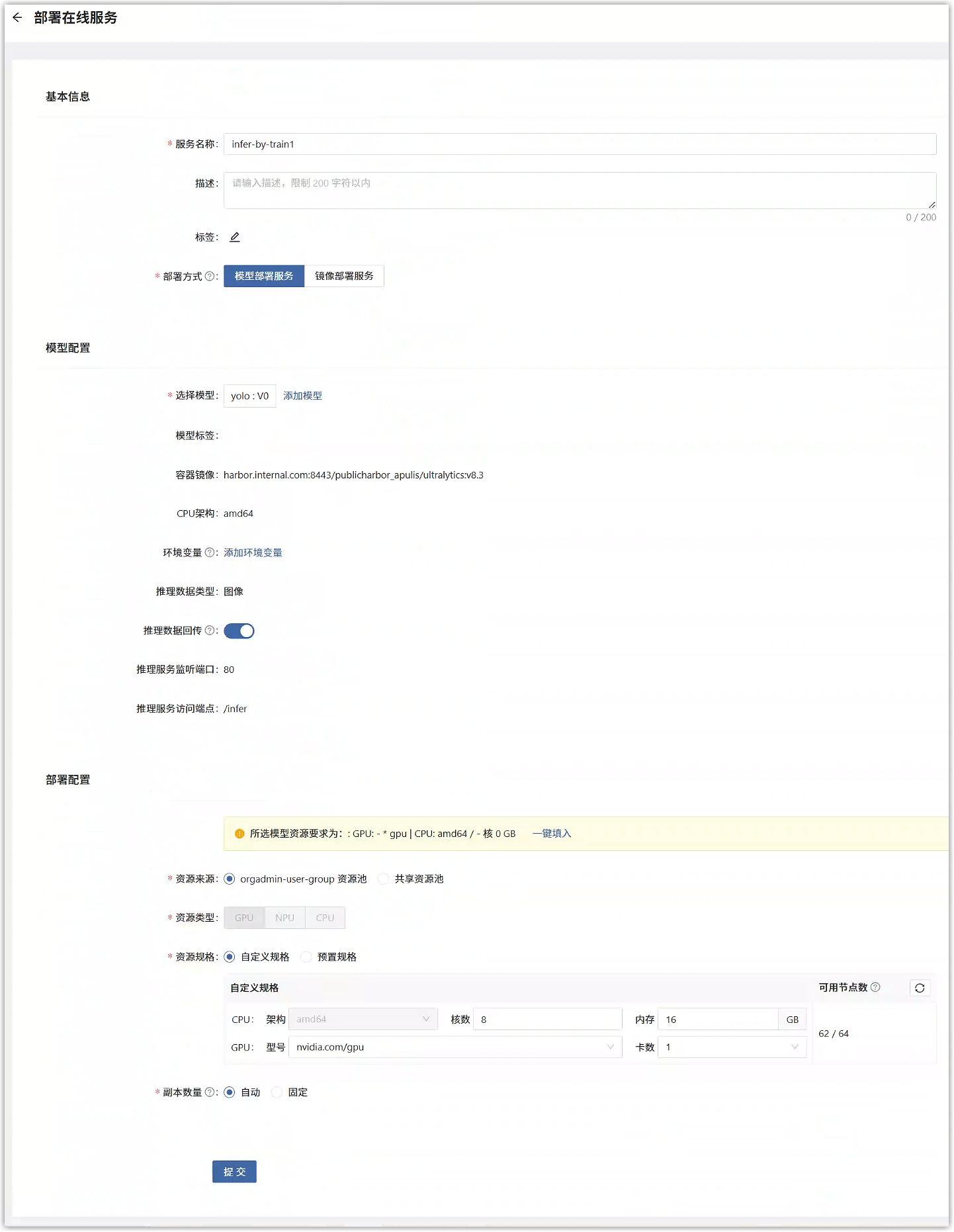
单击“提交”后,页面跳转到在线服务服务列表页面,在列表中能看到刚才部署的在线服务服务,点击此服务的名称,可以查看详情。
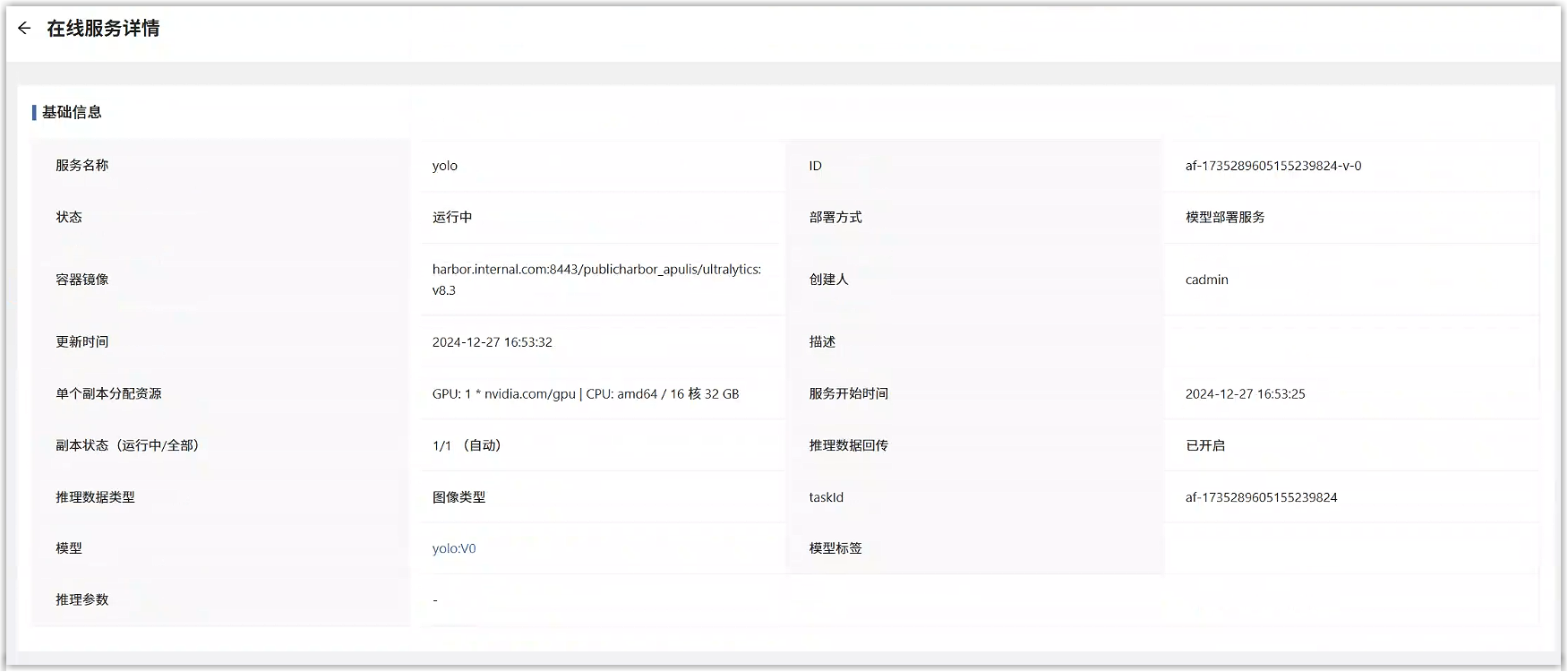
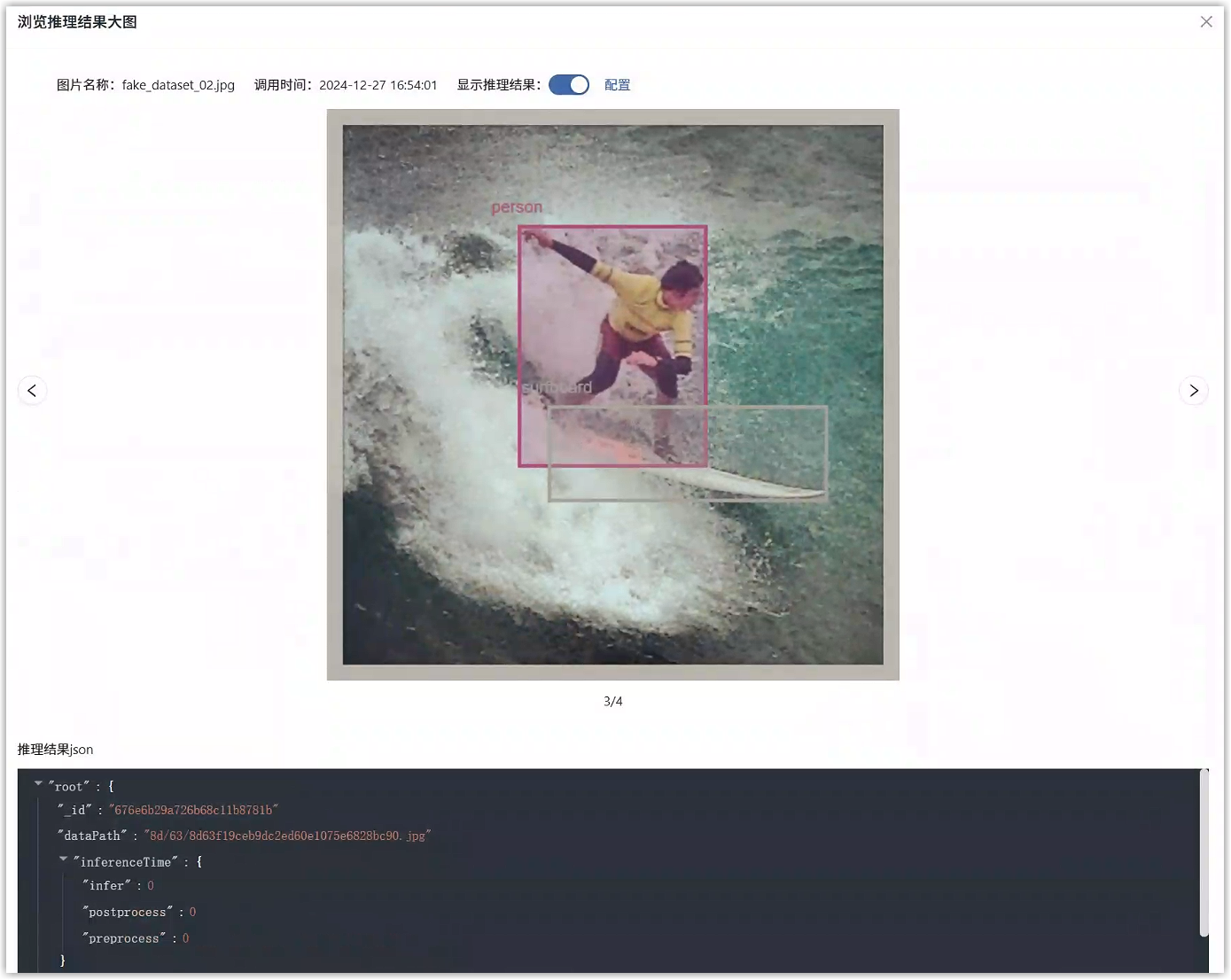
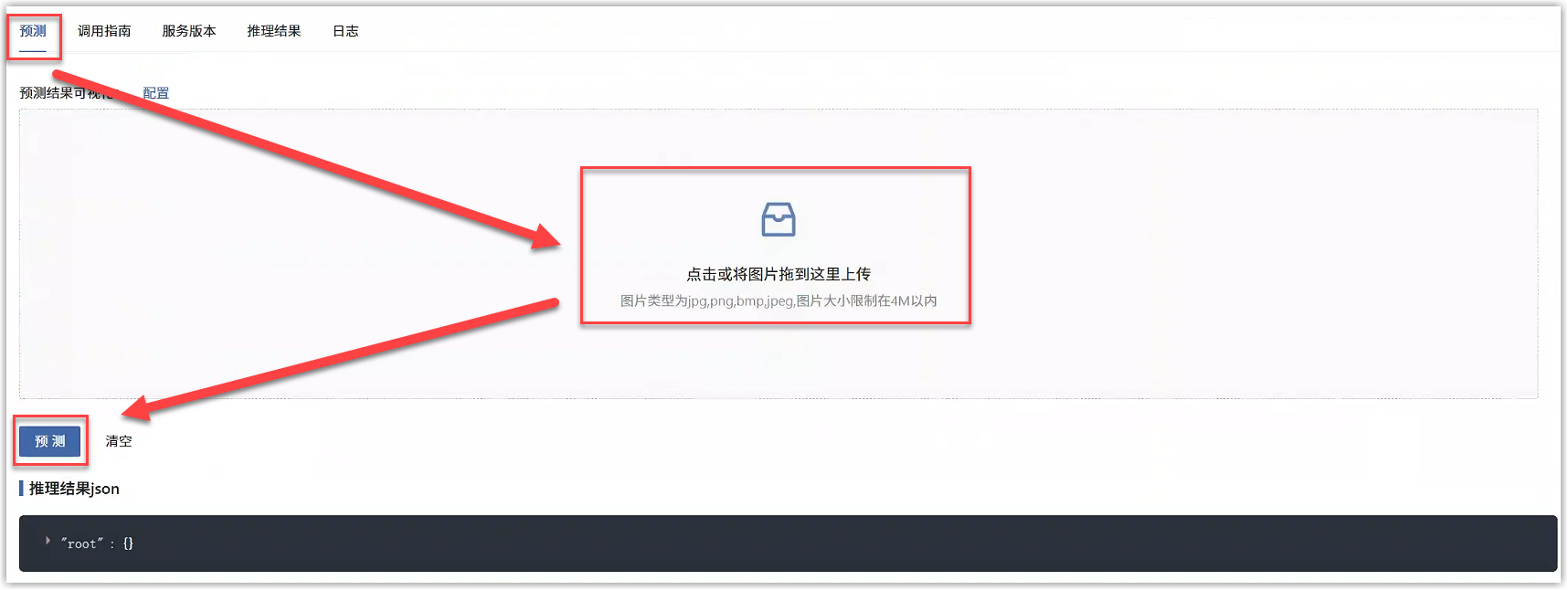
等待任务状态变为“运行中”,即模型部署成功,能够对外提供在线的推理服务了。详情页中,进入预测标签页,上传一张图片查看推理效果。
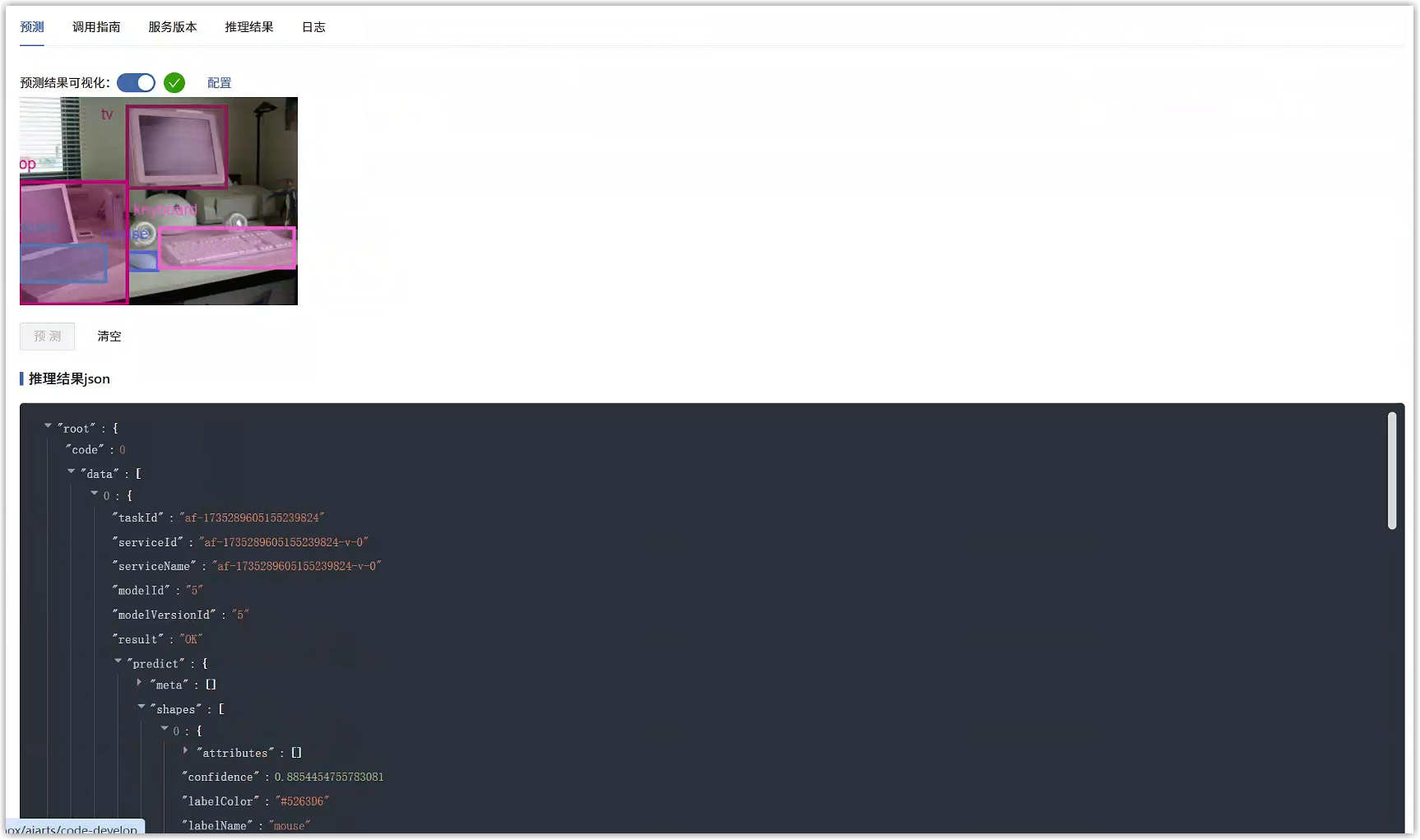
若能正确显示推理结果,则表明在线服务运行正常。
6 服务调用
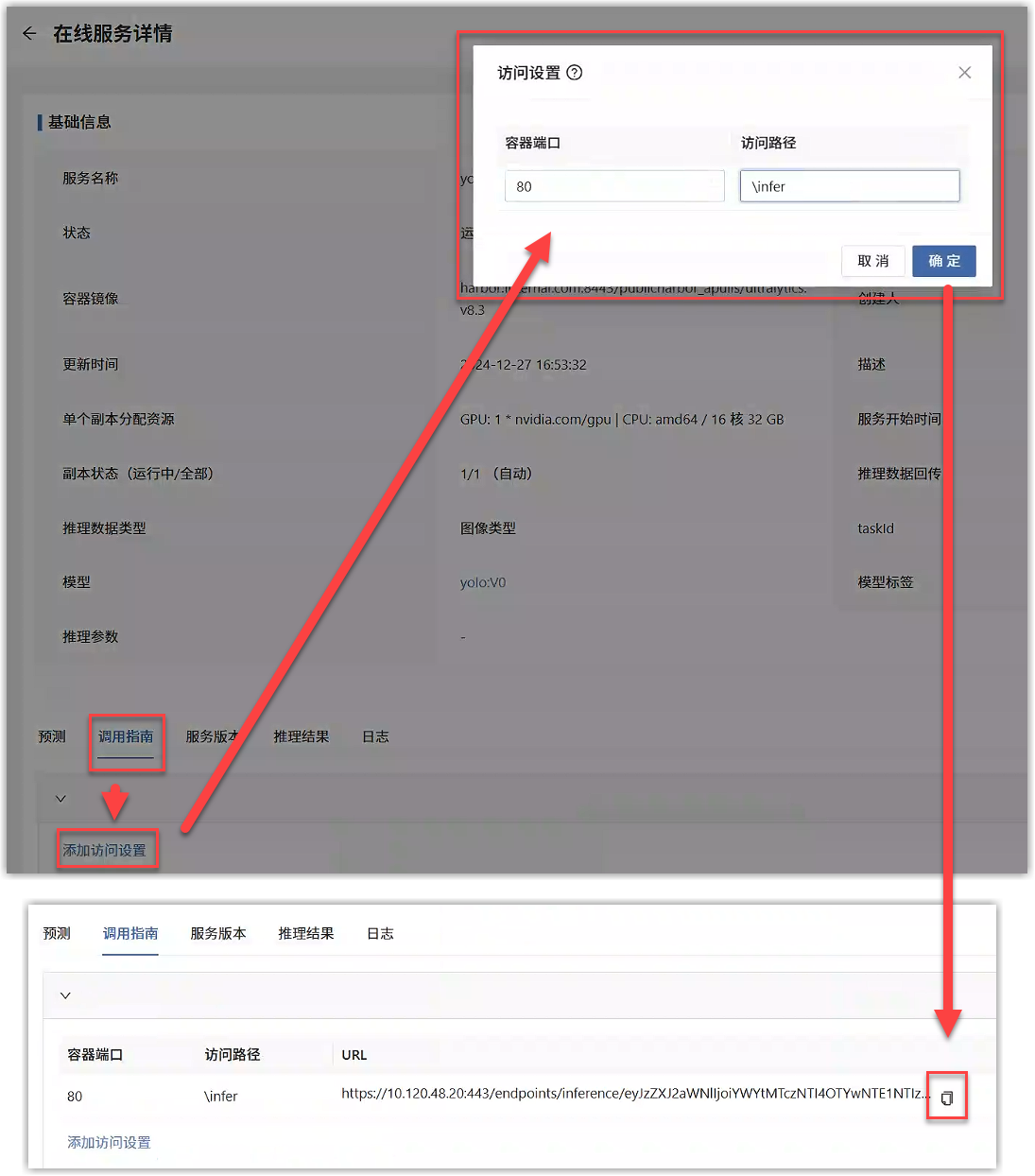
在线服务服务正常运行后,点击调用指南标签页,添加访问设置,输入推理模型的监听端口和访问断点并提交,即可以复制访问URL。
在本例中,使用HTTP方法POST,URL参数如下:
| 参数 | 值 |
|---|---|
| data | 图片的Base64编码 |
| name | 图片名称 |
在本例中,Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/json |
Body请求参数:
{
"requests": [
{
"data": "/9j/4R9ERXhpZgAA…………KVGxphQX/2Q==", // data 参数为图片的 Base64 编码
"name": "image01.jpg"
}
]
}
响应示例:
{
"code": 0,
"msg": "",
"data": [
{
"serviceName": "edgeinfer-1721201546190962310",
"modelId": "95",
"modelVersionId": "196",
"result": "OK",
"predict": {
"meta": [],
"shapes": [],
"tags": []
},
"inferenceTime": {
"infer": 0,
"postprocess": 0,
"preprocess": 0
},
"latency": 0,
"requestTime": 0,
"responseTime": 0
}
]
}
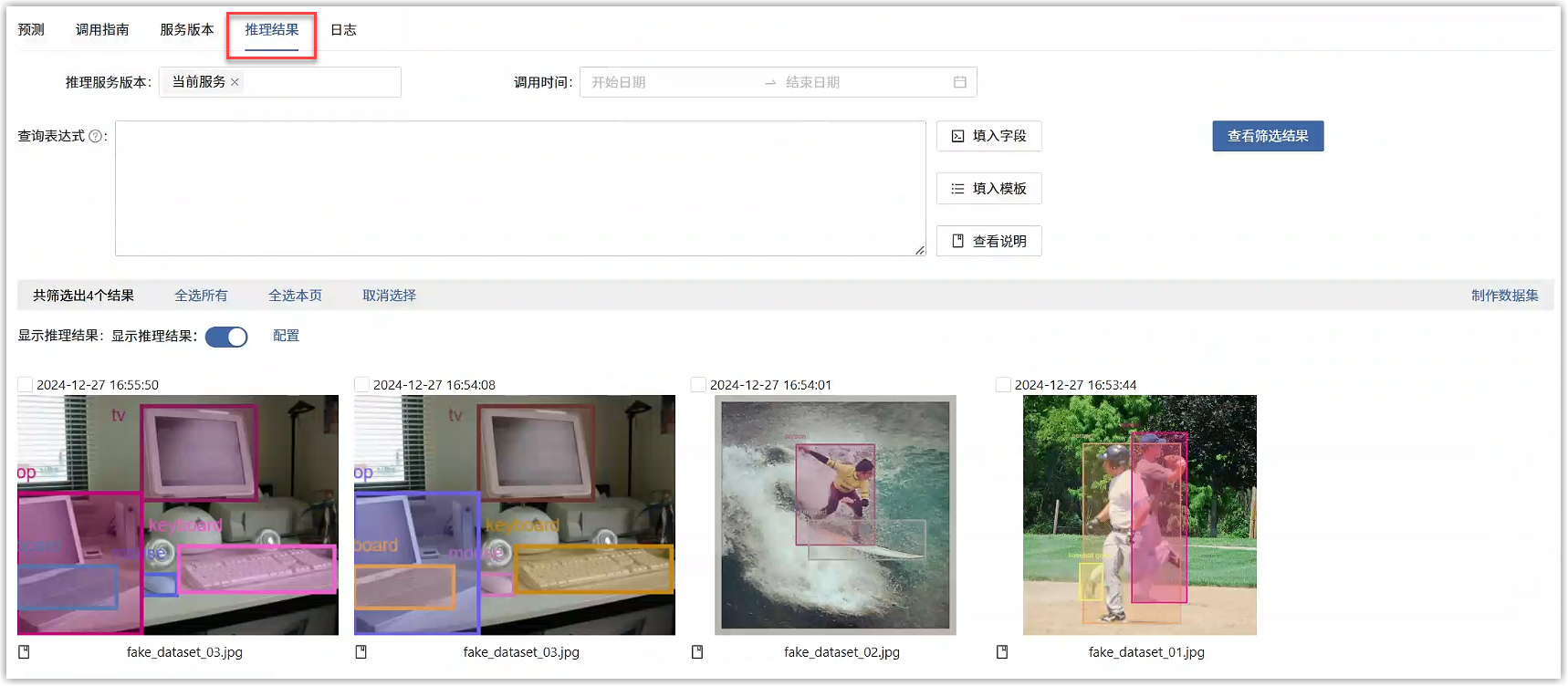
在推理结果标签页中,可以查看目标检测推理的结果,还可以筛选推理结果和制作数据集。