Slurm Job Management
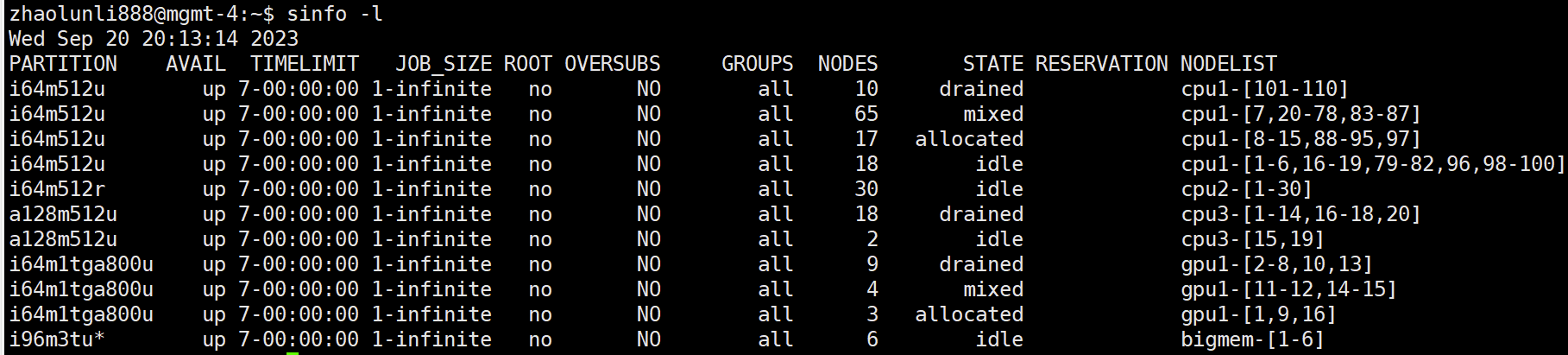
Displaying queue and node information: sinfo
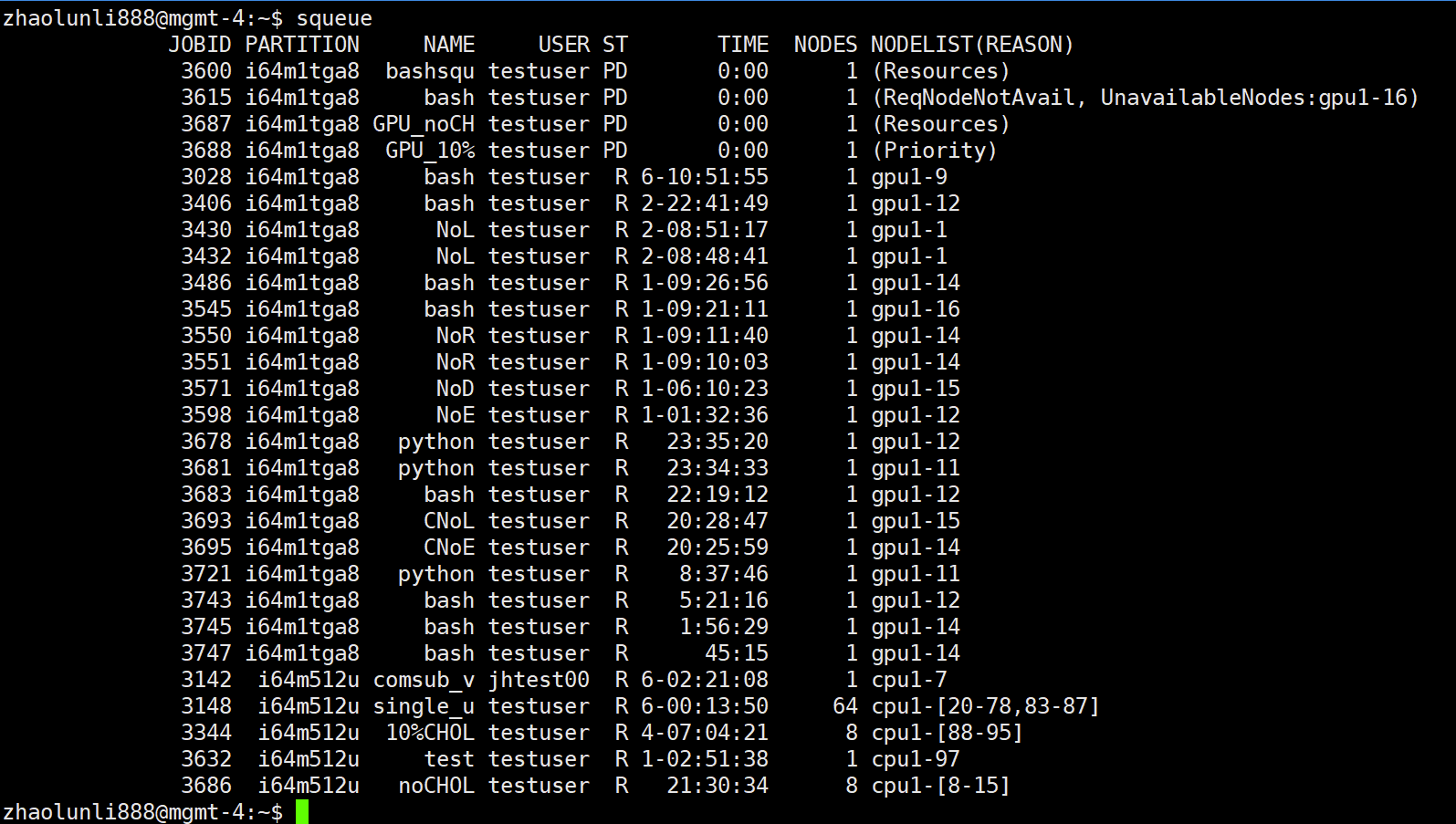
View information about jobs in the queue: squeue
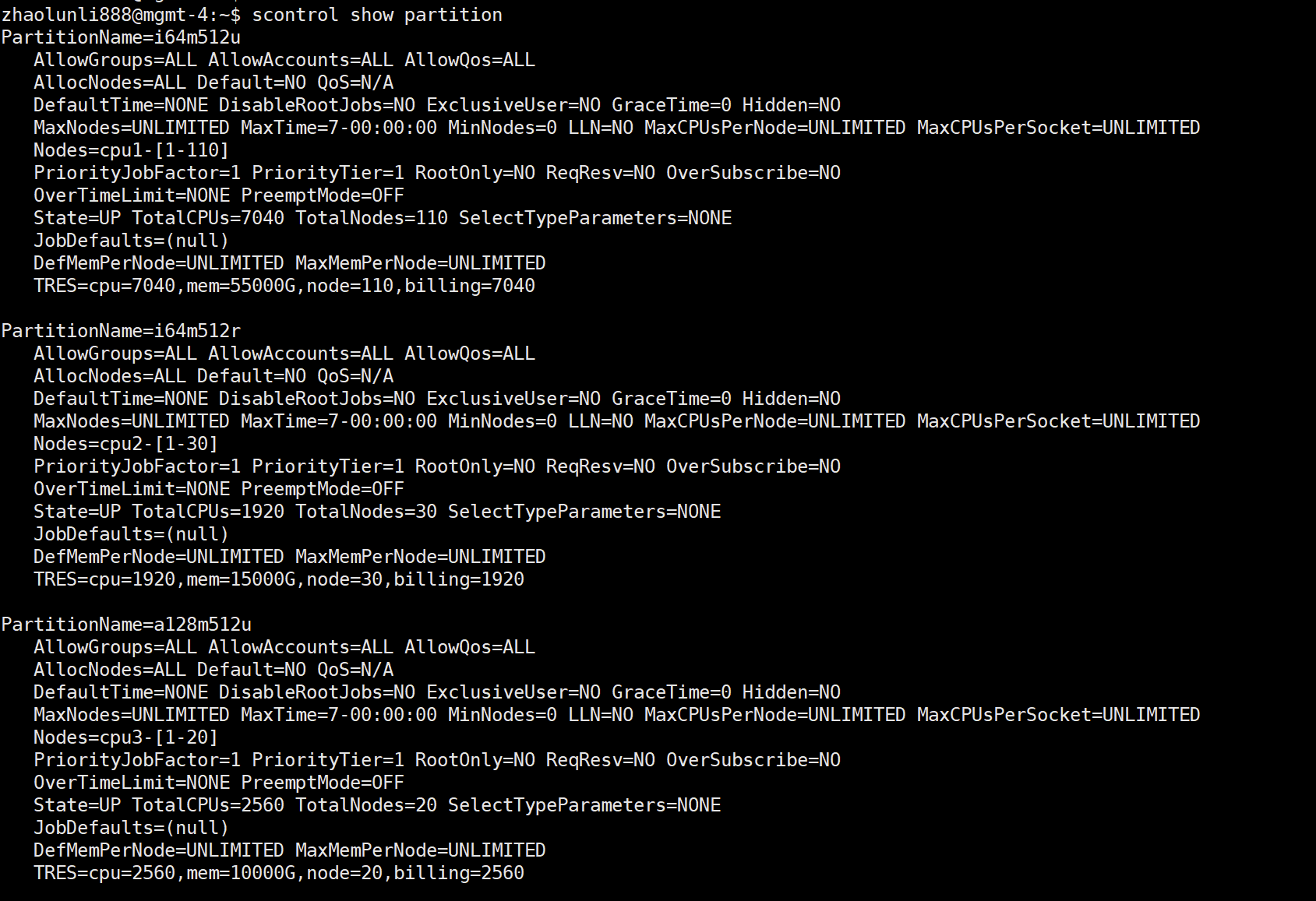
To view detailed partition (queue) information: scontrol show partition
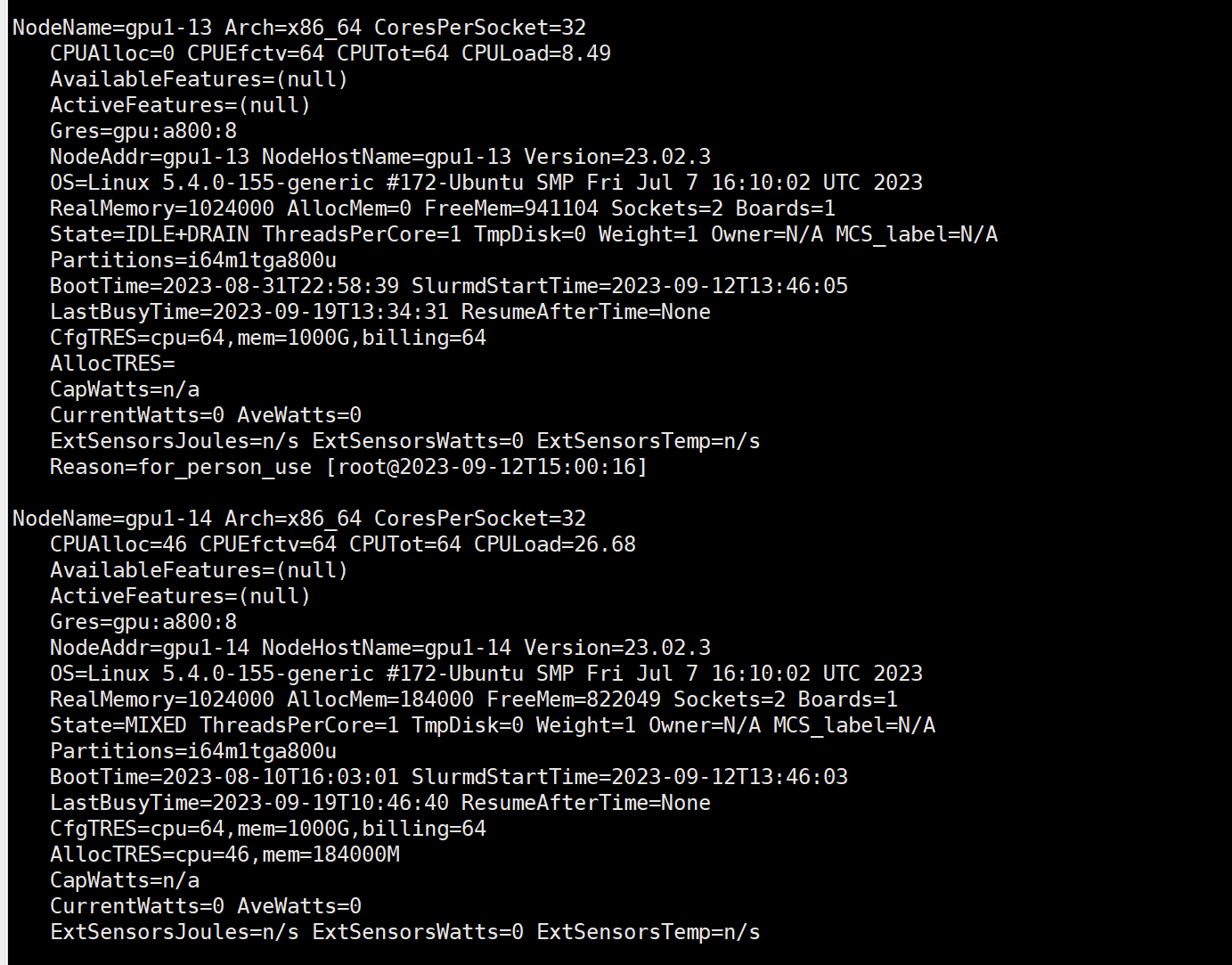
View detailed node information: scontrol show node
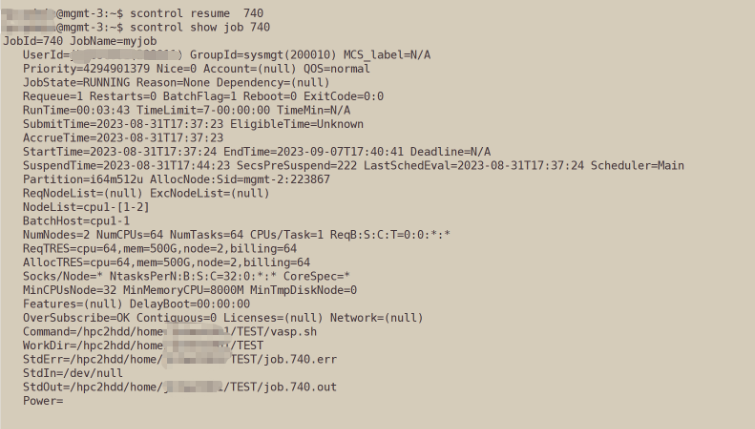
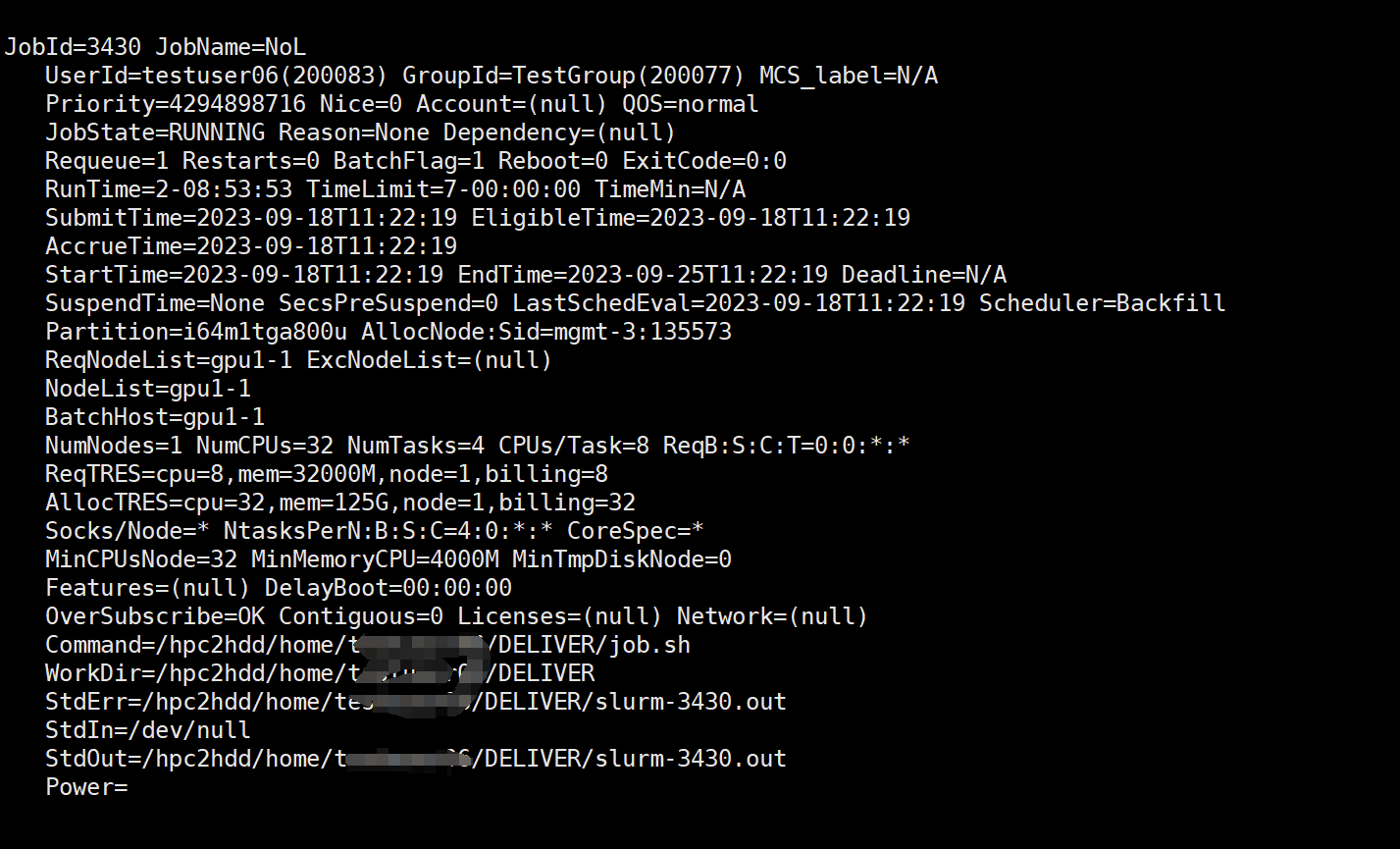
View detailed assignment information: scontrol show job $JOBID
View job dynamic output: speek
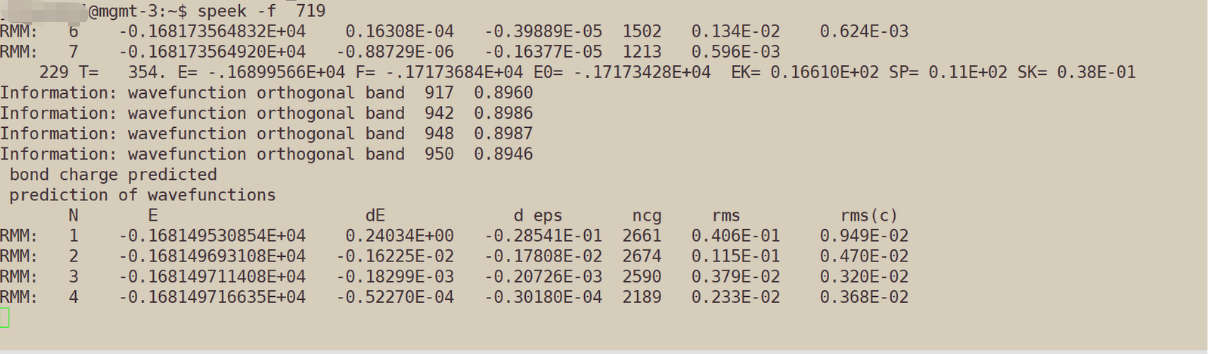
Note: This command does not come with slurm, it is encapsulated.
Terminate a job: scancel job_id

Hang a queued job: scontrol hold job_id
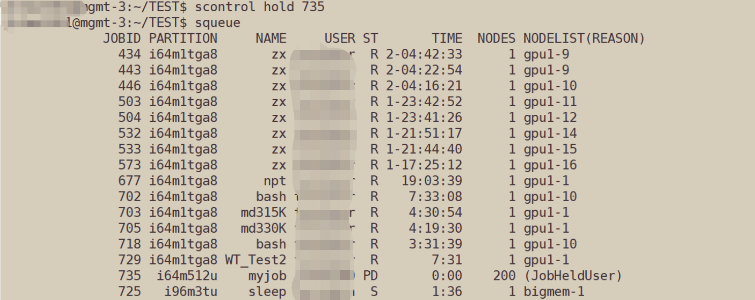
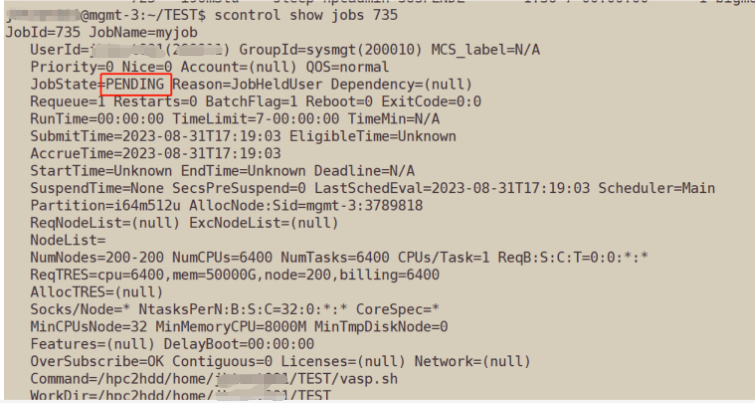
Continue a queued job: scontrol release _job_id

Suspend a running job: scontrol suspend job_id
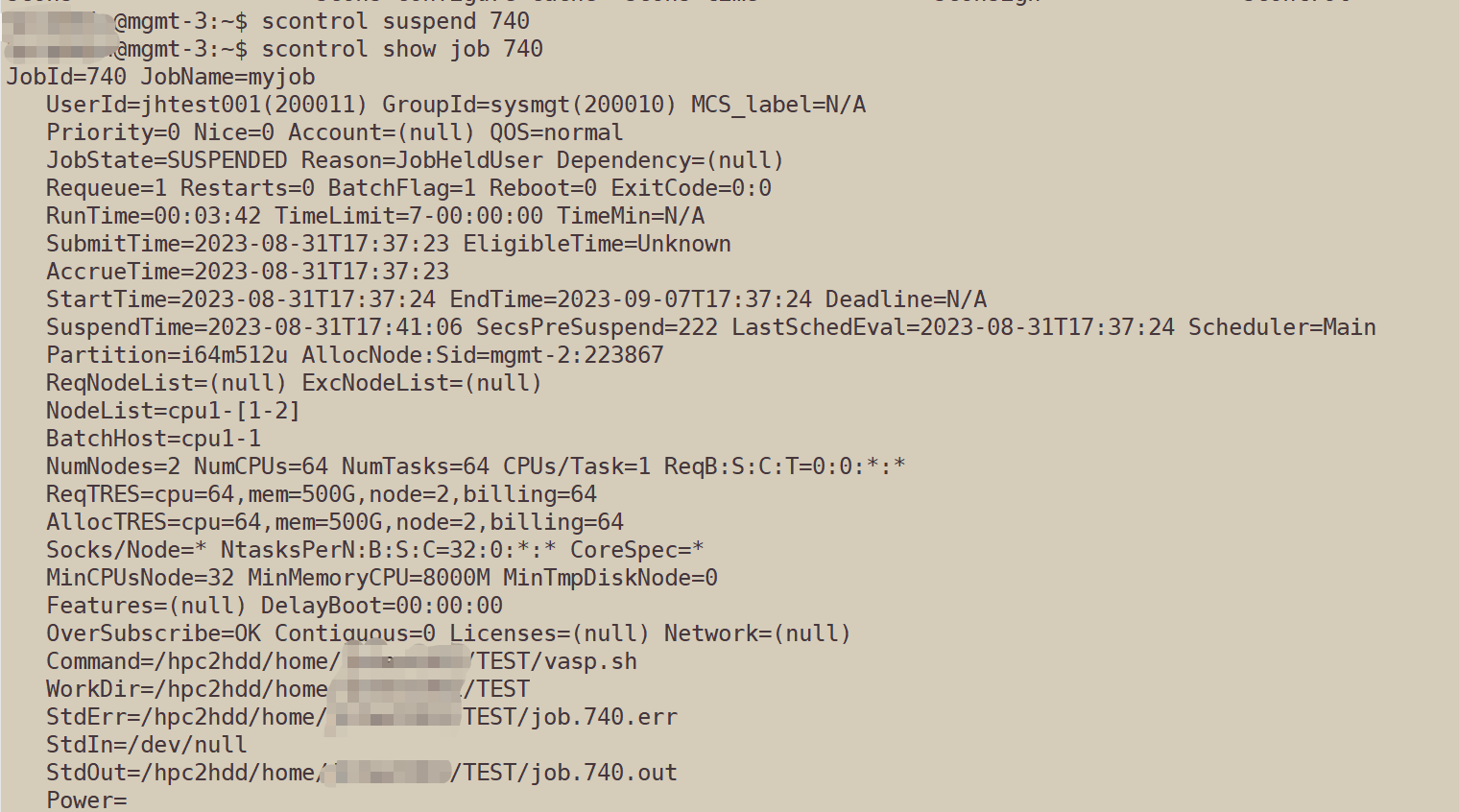
Resume a suspended job: scontrol resume job_id