12.12 Mindformers-chatglm-6b Training & Reasoning & Fine Tuning Summary
- Reasoning
- Catalog of weighted documents:
1.1. Way 1: AutoClass You can use the AutoClass interface to get the corresponding model/tokenizer instance by model name, and automatically download and load the weights. from_pretrained() interface will automatically download the pre-trained model from the cloud, storage path: current execution script directory under . /checkpoint_download/glm When running pipeline inference for the first time, you need to compile the model and wait for some time. from mindformers import AutoModel, AutoTokenizer, TextGenerationPipeline model = AutoModel.from_pretrained("glm_6b_chat") tokenizer = AutoTokenizer.from_pretrained("glm_6b") pipeline = TextGenerationPipeline(model, tokenizer, max_length=2048) print(pipeline("hello"))
#eg:[{'text_generation_text': ['Hello, hello, hello! I'm ChatGLM-6B, an artificial intelligence assistant, nice to meet you, feel free to ask me any questions.']}] 1.2. Approach 2: pipeline It is also possible to construct a pipeline without instantiating a constructive model, by specifying the task model and the model name. The pipeline can also use the glm_6b_chat model to accelerate the inference from mindformers import pipeline task_pipeline = pipeline(task="text_generation", model="glm_6b_chat", max_length=2048) print(task_pipeline("hello"))
#eg:[{'text_generation_text': ['Hello, hello, hello! I'm ChatGLM-6B, an artificial intelligence assistant, nice to meet you, feel free to ask me any questions.']}] 1.3. Approach III: API interface import time import mindspore as ms import numpy as np from mindformers.models.glm import GLMConfig, GLMChatModel from mindformers.models.glm.chatglm_6b_tokenizer import ChatGLMTokenizer from mindformers.models.glm.glm_processor import process_response
config = GLMConfig( position_encoding_2d=True, use_past=True, is_npu_acceleration=True, )
def chat_glm(): ms.set_context(mode=ms.GRAPH_MODE, device_target="Ascend", device_id=7) model = GLMChatModel(config) ms.load_checkpoint("./checkpoint_download/glm/glm_6b.ckpt", model) tokenizer = ChatGLMTokenizer('./checkpoint_download/glm/ice_text.model')
prompts = [“Hello”, “Please tell me about Huawei”]
history = []
for query in prompts:
if not history:
prompt = query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n问:{}\n答:{}\n".format(i, old_query, response)
prompt += "[Round {}]\n问:{}\n答:".format(len(history), query)
inputs = tokenizer(prompt)
start_time = time.time()
outputs = model.generate(np.expand_dims(np.array(inputs['input_ids']).astype(np.int32), 0),
max_length=config.max_decode_length, do_sample=False, top_p=0.7, top_k=1)
end_time = time.time()
print(f'generate speed: {outputs[0].shape[0]/(end_time-start_time):.2f} tokens/s')
response = tokenizer.decode(outputs)
response = process_response(response[0])
history = history + [(query, response)]
print(response)
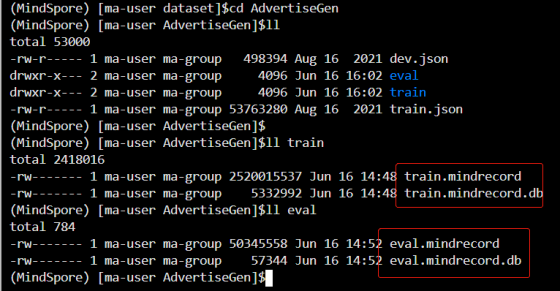
if name == "main": chat_glm() 2. Fine-tuning 2.1.Fine-tuning dataset 1.ADGEN dataset download address: https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1 Unzip the dataset in a custom specified directory eg: /home/ma-user/work/dataset/ 2. dataset to mindrecord format #Generate training dataset python adgen_dataset.py --input_file /home/ma-user/work/dataset/AdvertiseGen/train.json --vocab_file /home/ma-user/work/mindformers/mycode/glm/checkpoint_download/glm/ice_text.model --output_file /home/ma-user/work/dataset/AdvertiseGen/train/train.mindrecord --max_source_length 64 --max_target_length 64 --mode train
#Generate assessment datasets
python adgen_dataset.py --input_file /home/ma-user/work/dataset/AdvertiseGen/dev.json --vocab_file /home/ma-user/work/mindformers/mycode/glm/checkpoint_download/glm/ice_text.model --output_file /home/ma-user/work/dataset/AdvertiseGen/eval/eval.mindrecord --max_source_length 256 --max_target_length 256 --mode eval
2.2. Bare-metal environment to generate HCCL files (reference) Run mindformers/tools/hccl_tools.py to generate json file for RANK_TABLE_FILE; #step1: Run the following commands on the machine to generate the respective json file for RANK_TABLE_FILE python ./mindformers/tools/hccl_tools.py --device_num "[0,8)" Note: If you are using ModelArts' notebook environment, you can get the rank table directly from the /user/config/jobstart_hccl.json path without manually generating it. RANK_TABLE_FILE Standalone 8-card reference example: { "version":"1.0", "server_count":"1", "server_list":[ { "server_id":"xx.xx.xx.xx", "device":[ {"device_id":"0","device_ip":"192.1.27.6","rank_id":"0"}, {"device_id":"1","device_ip":"192.2.27.6","rank_id":"1"}, {"device_id":"2","device_ip":"192.3.27.6","rank_id":"2"}, {"device_id":"3","device_ip":"192.4.27.6","rank_id":"3"}, {"device_id":"4","device_ip":"192.1.27.7","rank_id":"4"}, {"device_id":"5","device_ip":"192.2.27.7","rank_id":"5"}, {"device_id":"6","device_ip":"192.3.27.7","rank_id":"6"}, {"device_id":"7","device_ip":"192.4.27.7","rank_id":"7"}], "host_nic_ip":"reserve" } ], "status":"completed" } 2.3. Full-parameter fine-tuning 2.3.1. run_mindformers script to start full-parameter fine-tuning Full-parameter fine-tuning uses the configs/glm/run_glm_6b_finetune.yaml configuration file, which defines the configuration items required for fine-tuning. Modify the dataset/model weight configuration path:
dataset: Modify the dataset_dir of train_dataset in the mindformers/configs/glm/run_glm_6b_finetune.yaml script to the path of the dataset generated in the previous section.
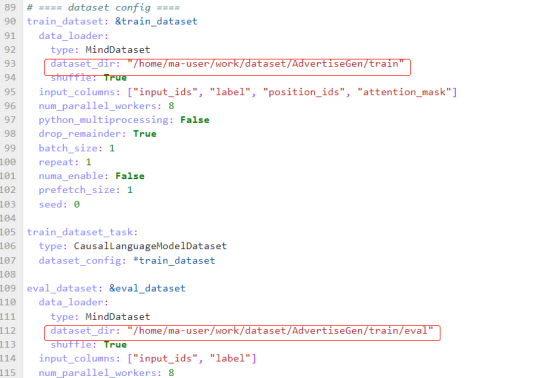
Load pre-trained model weights: Modify load_checkpoint in the mindformers/configs/glm/run_glm_6b_finetune.yaml script to be the path of pre-trained model weights.

- Launch the full-parameter fine-tuning script: cd scripts #Usage Help: bash run_distribute.sh [RANK_TABLE_FILE][CONFIG_PATH] [DEVICE_RANGE][RUN_STATUS] bash run_distribute.sh /user/config/nbstart_hccl.json ../configs/glm/run_glm_6b_finetune.yaml '[0,8]' finetune #Replace rank_table_file here with the actual path, in this case for a notebook environment. Parameter description RANK_TABLE_FILE: distributed json file generated by mindformers/tools/hccl_tools.py CONFIG_PATH: configuration file for glm/run_glm_6b.yaml under the configs folder DEVICE_RANGE: the range of cards to be distributed on a single machine, e.g. '[0,8]' for an 8-card distribution, not including 8 itself. RUN_STATUS: for task run state, support keyword train\finetune\eval\predict Note: Due to the large model of GLM6B, it is not possible to run on a single card, only the distributed startup script is provided here
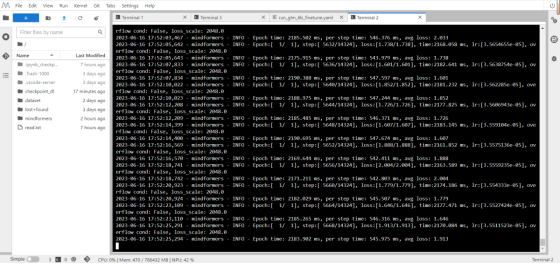
- training log:
2.4.LoRA Low Parameter Fine-tuning Full-parameter fine-tuning can achieve good results on the fine-tuned dataset, but there is the phenomenon of forgetting the pre-training knowledge Therefore, it is recommended to use the low-parameter fine-tuning algorithm, freezing the original model weights, and training only on a small-scale number of parameters, which can achieve good results on the fine-tuned dataset and alleviate the phenomenon of model forgetting. 2.4.1. run_mindformers script to start LoRA low-parameter fine-tuning Low-parameter fine-tuning with the LoRA algorithm is performed using the configs/glm/run_glm_6b_lora.yaml configuration file, which contains the configuration items required for the LORA low-parameter fine-tuning algorithm Modify the dataset/model weight configuration path:
dataset: Modify the dataset_dir of train_dataset in mindformers/configs/glm/run_glm_6b_lora.yaml script to the path of the dataset generated in the previous section.
Load pre-trained model weights: Modify load_checkpoint in mindformers/configs/glm/run_glm_6b_lora.yaml script to the path of pre-trained model weights. Start the LoRA low parametric fine-tuning script (4 cards): Note: Due to the reduction of memory required for low-parameter fine-tuning, 4 cards can be used for training in parallel here, and the rank table file required for 4-card training needs to be regenerated. The number of cards should be configured according to the actual situation. Notebook generates hccl json file by default, so the number of cards should be configured according to the actual situation. cd scripts #Usage Help: bash run_distribute.sh [RANK_TABLE_FILE][CONFIG_PATH] [DEVICE_RANGE][RUN_STATUS] bash run_distribute.sh /path/to/hccl_4p_0123_xxx.json ../configs/glm/run_glm_6b_lora.yaml '[0,4]' finetune #Replace here rank_table_file with the actual path. Parameter Description: Compare to the full-parameter fine-tuning startup method, only change the CONFIG_PATH entry to the glm/run_glm_6b_lora.yaml configuration file under the configs folder, indicating that the interface is used to perform the Path to the training log: mindformers/output/log checkpoint storage path: mindformers/output/checkpoint 3.LoRA low parameter fine-tuning results:

Assessment 3.1. Model weights file unification The weight files obtained from fine-tuning are the weights cut according to the model cut strategy, we need to manually unify the cut weights for evaluation and reasoning. Get the model cut strategy file: When executing the full-parameter fine-tuning script, after the model is compiled, a cut strategy file named ckpt_strategy.ckpt will be generated under the run path and saved; the path and name of the file are configured in the configuration file. MindSpore provides an interface to convert the model weights to be sliced according to the slicing strategy, https://www.mindspore.cn/docs/zh-CN/r2.0/api_python/mindspore/mindspore.transform_checkpoints.html. Execute the following python script to synthesize the eight model files into a single one from mindspore import transform_checkpoints transform_checkpoints( src_checkpoints_dir="./output/checkpoint/", # original cut weights folder dst_checkpoints_dir="./target_checkpoint/", # Target path ckpt_prefix="glm-6b", # .ckpt文件前缀名 src_strategy_file=“ckpt_stragery.ckpt”, # Path to the slice strategy file from step 1 dst_strategy_file=None # None means no slicing, weights are unity ) After the execution of the above code to generate the weight file is about 63G + ckpt file, you need to execute the following script for cropping, to get the file is about 13G +, LoRa fine-tuning does not exist in this operation (because this operation uses Mindspore1.10) import mindspore as ms from mindspore import context context.set_context(device_target="CPU")
from mindformers.tools.register import MindFormerConfig from mindformers.models.glm import GLMConfig,GLMChatModel
#Using automodel loads the pre-trained model weights and takes a long time. Use the following approach without loading the weights config = GLMConfig(MindFormerConfig('./checkpoint_download/glm/glm_6b.yaml')) model_from_config = GLMChatModel(config) print("Model loading complete") ckpt_path = "/home/ma-user/work/mindformers/target_checkpoint/rank_0/glm-6b.ckpt" param_dict = ms.load_checkpoint(ckpt_path) print("Model loading complete") new_param_dict = {} for key, value in param_dict.items(): if "adam" not in key.lower(): new_param_dict[key] = value print("Parameter filtering complete")
paramnot_load, = ms.load_param_into_net(model_from_config, param_dict)
ms.load_param_into_net(model_from_config, param_dict) print("Loading complete") ms.save_checkpoint(model_from_config, "/home/ma-user/work/mindformers/target_checkpoint/rank_0/glm-6b_new.ckpt")
Note: the transform_checkpoints interface is only supported by mindspore 2.0 or above, if the current hardware environment only supports 2.0 or below, you can create a new conda environment and install the cpu version of mindspore 2.0 to execute the script. In addition, for the non-2.0 version of mindspore, the generated cut strategy file will not contain the frozen weights during the low-parameter fine-tuning, which will lead to the failure of merging the weight files; at this time, we need to comment out the code about the frozen weights of LoRA in the mindformers/models/glm/glm.py file, then re-run the fine-tuning script to obtain the correct cut strategy file and stop the training process; the relevant code in the mindformers/models/glm/glm.py file can also be commented out and the training process can be stopped after getting the correct cut strategy file. After getting the correct cut strategy file, stop the training process; the relevant code is as follows
@MindFormerRegister.register(MindFormerModuleType.MODELS) class GLMForPreTrainingWithLora(GLMForPreTraining): """GLM Model for pretraining with LoRA
Args: config (GLMConfig): The config of network. """
def init(self, config: GLMConfig = None, pet=None, **kwargs): _ = kwargs super().init(config)
# get Pet tuning model.
self.pet = pet
self.pet.pet_config.reg_rules = r'.*query_key_value*'
self.transformer = LoraAdapter.get_pet_model(self.transformer, self.pet.pet_config)
# freeze pretrained model
PetAdapter.freeze_pretrained_model(self, self.pet.pet_type) # Comment this line to generate a new strategy file
Non-version 2.0, Mindspore version 1.10, perform weight file merge without exception merge normally, merge weight file about 1.2g, use the file for evaluation before reporting an error, the error message is as follows:
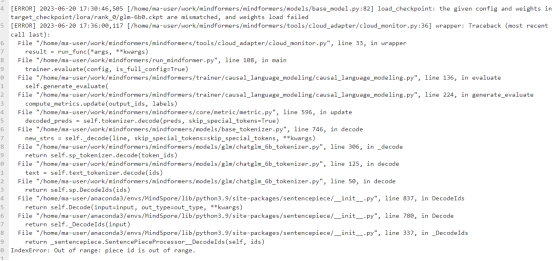
3.2. fine-tune weights using full parameters
3.2.1. run_mindformers start eval
To use full-parameter fine-tuning weights, start the following shell script to perform a single-card evaluation
Configure configs/glm/run_glm_6b_infer.yaml to configure the glm model inference, which makes the evaluation faster.
python run_mindformer.py --config configs/glm/run_glm_6b_infer.yaml --run_mode eval --load_checkpoint /path/to/glm_6b.ckpt --eval_dataset_dir /path/to/data/AdvertiseGen/adgen_dev.mindrecord --device_id 0
parameters:
config: Specify the name of the configuration file to be used for evaluation, in this case configs/glm/run_glm_6b_infer.yaml
run_mode: Specify the execution mode, in this case eval, which means evaluation mode.
load_checkpoint: Specify the path of the checkpoint to be loaded, here is /path/to/glm_6b.ckpt, replace with the real path of the weight to be loaded.
eval_dataset_dir: Path to the evaluated dataset.
device_id: Specify the device number to be used (starting from 0)
The evaluation metrics bleu-4, rouge-1, rouge-2, rouge-l are printed when the evaluation is complete
Note: Since the default evaluation metrics are obtained by generating the complete text and comparing it with the expected text, the evaluation speed will be limited by the model size and text generation speed, and the evaluation process may be slow.
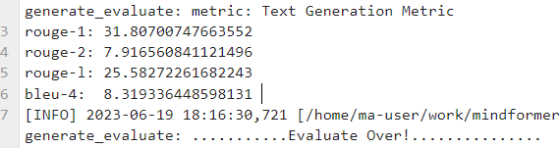
Eval Test Results
63.5G uncropped version of ckpt:
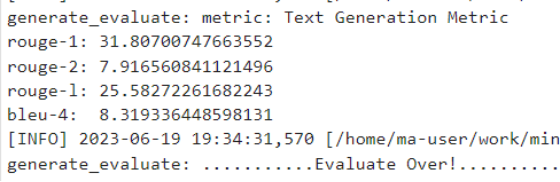
13.5G cropped ckpt:
3.3. fine-tuning weights using LoRA low parameters 3.3.1. run_mindformers to start lora eval To use LoRA low-parameter fine-tuning weights, start the following shell script to perform a single-card evaluation Configuration file selection configs/glm/run_glm_6b_lora_infer.yaml glm_lora model inference configuration, this configuration can be used for the lora model and evaluates faster
python run_mindformer.py --config configs/glm/run_glm_6b_lora_infer.yaml --run_mode eval --load_checkpoint /path/to/glm_6b_lora.ckpt --eval_dataset_dir /path/to/data/AdvertiseGen/adgen_dev.mindrecord --device_id 0 The parameters are the same as above, the path should be replaced with the actual path 3.4. Model weight transformation (reference) The glm in this repository is obtained from HuggingFace's https://huggingface.co/THUDM/chatglm-6b based on the following steps: Clone the chatglm-6b code repository and download the distributed model files. git lfs install git clone https://huggingface.co/THUDM/chatglm-6b Execute the python script to merge the model weights.
from transformers import AutoModel import torch as pt
pt_ckpt_path="Your chatglm-6b path" model = AutoModel.from_pretrained(pt_ckpt_path, trust_remote_code=True).half() pt_pth_path = "pt_glm_6b.pth" pt.save(model.state_dict(), pt_pth_path) Execute the conversion script to get the converted output file ms_glm_6b.ckpt。 python mindformers/models/glm/convert_weight.py --pt_ckpt_path "replace your ptroch pth path" --ms_ckpt_path ./ms_glm_6b.ckpt