Model Publishing
After the model algorithm code development is completed, the model can be published to the model library. This is convenient for version management, re-training and evaluation, and sharing with other users.
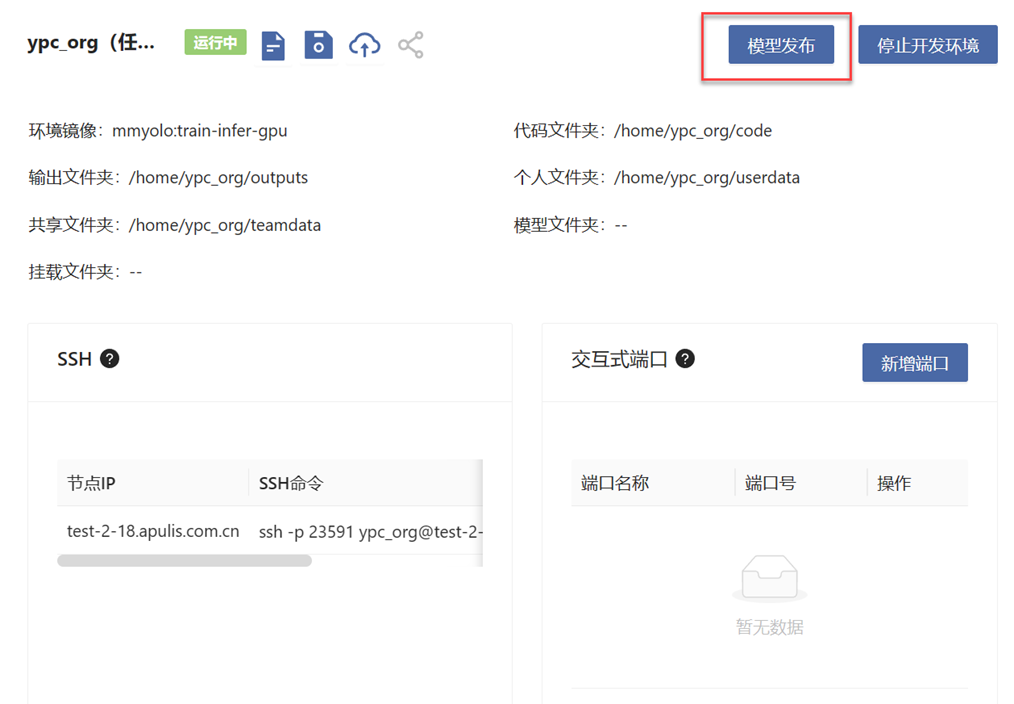
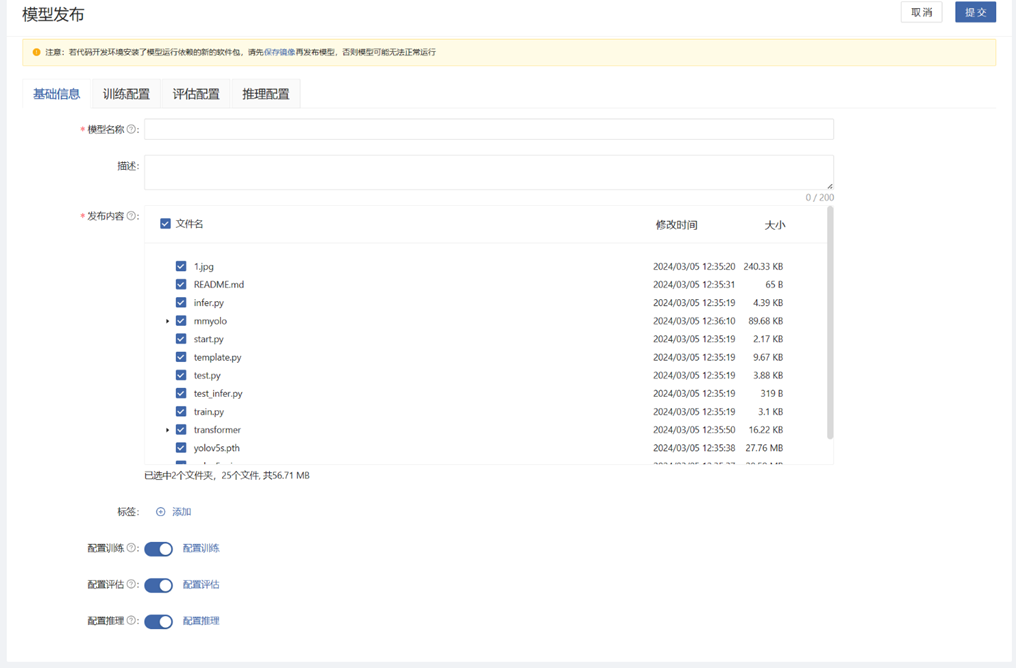
In the development environment, click the "Publish Model" button to publish. On the model publishing page, you can configure the basic information, training configuration, evaluation configuration, and inference configuration of the model.
If new software packages on which the model runs are installed in the code development environment, save the image first before publishing the model. Otherwise, the model may not run properly.
Training Configuration
If model training is required after publishing, configuration is needed. It can also be configured in the model library after publishing. When using this model for model training, the task will be started according to the following configuration information:
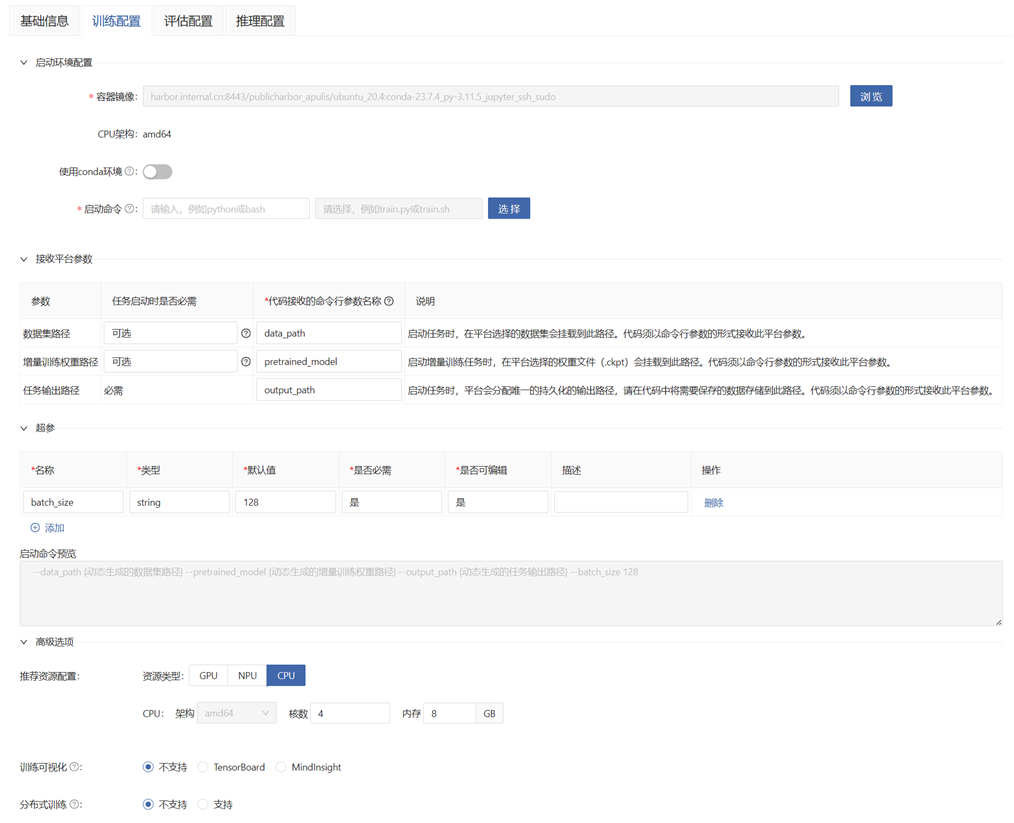
- Container Image: The image used when starting the task. The image used in the development environment is filled by default.
- CPU Architecture: The CPU architecture used by the image and resources is filled automatically.
- Use Conda Environment: Whether to use the Conda environment for training. If the Conda environment is used in code development and the image is not saved, turn it on. It should be noted that after the model is published, do not delete or modify this Conda environment casually. Otherwise, the task may fail to run (if you want to avoid this situation, save the development environment as an image and use the saved image for training).
- Startup Command:
- Startup Entry: The startup entry within the image. If the startup script is a
.pyfile, the startup entry can be set aspython; if the startup script is a.shfile, the startup entry can be set asbash. - Startup Script: Select the startup script file from the
codefolder of the published content. Only.pyor.shformats are supported.
- Startup Entry: The startup entry within the image. If the startup script is a
- Received Platform Parameters:
- Dataset Path: The mounting path of the model training dataset.
- Incremental Training Weight Path: The mounting path of the incremental training weight file.
- Task Output Path: The output path of the model training task. The platform will allocate a unique persistent output path. Please store the data that needs to be saved in the code to this path.
- Hyperparameters: The hyperparameters for model training are passed to the startup script in the form of command-line parameters.
- Startup Command Preview: You can preview the complete startup command.
- Resource Type: The type of resources used for model training. The resources used in the development environment will be filled automatically.
- CPU, GPU, NPU: The recommended resource specifications for model training. The resources used in the development environment will be filled automatically.
- Training Visualization: Select the supported visualization type. Please store the visualization output in the "Task Output Path" of the received platform parameters in the code, and the platform will automatically read it.
- Distributed Training: If the code supports distributed training, you can select this option.
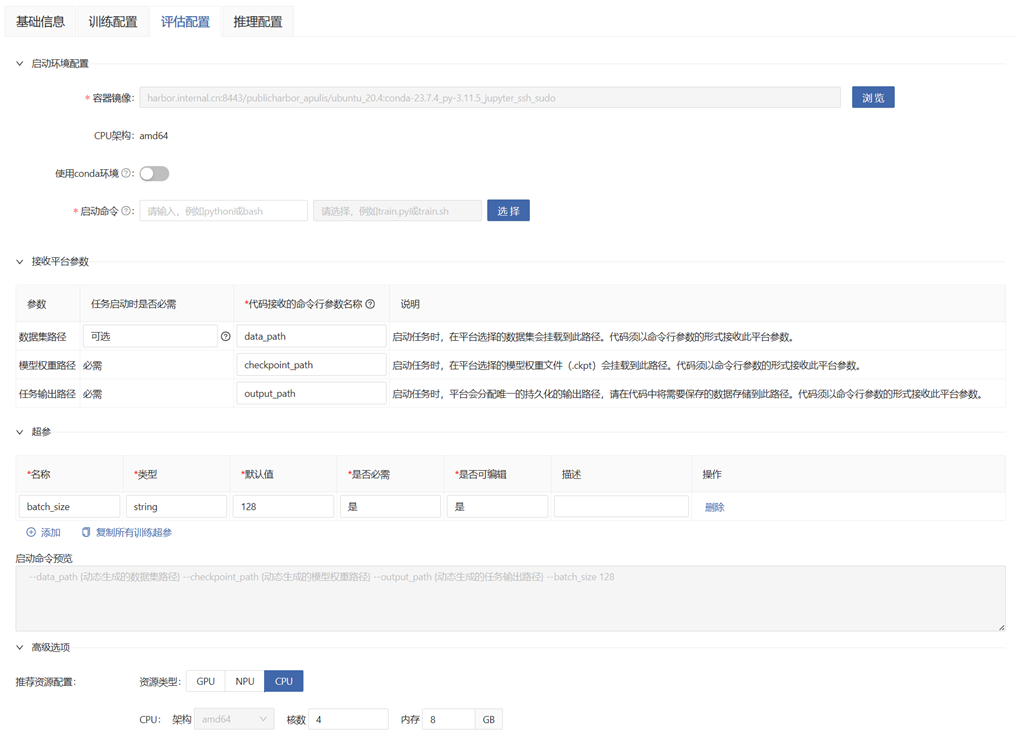
Evaluation Configuration
If model evaluation is required after publishing, configuration is needed. It can also be configured in the model library after publishing. When using this model for model evaluation, the task will be started according to the following configuration information:
Container Image, CPU Architecture, Use Conda Environment, Startup Command, Hyperparameters, Startup Command Preview, Resource Type: The same as the training configuration.
Received Platform Parameters:
Dataset Path: The mounting path of the model evaluation dataset.
Model Weight Path: The mounting path of the weight file generated by model training.
Task Output Path: The output path of the model evaluation task. The platform will allocate a unique persistent output path. Please store the data that needs to be saved in the code to this path.
Inference Configuration
If model inference is required after publishing, configuration is needed. It can also be configured in the model library after publishing. When using this model for model inference, the task will be started according to the following configuration information:
Container Image, CPU Architecture, Use Conda Environment, Startup Command, Hyperparameters, Startup Command Preview, Resource Type: The model inference task will be started according to the following configuration information:
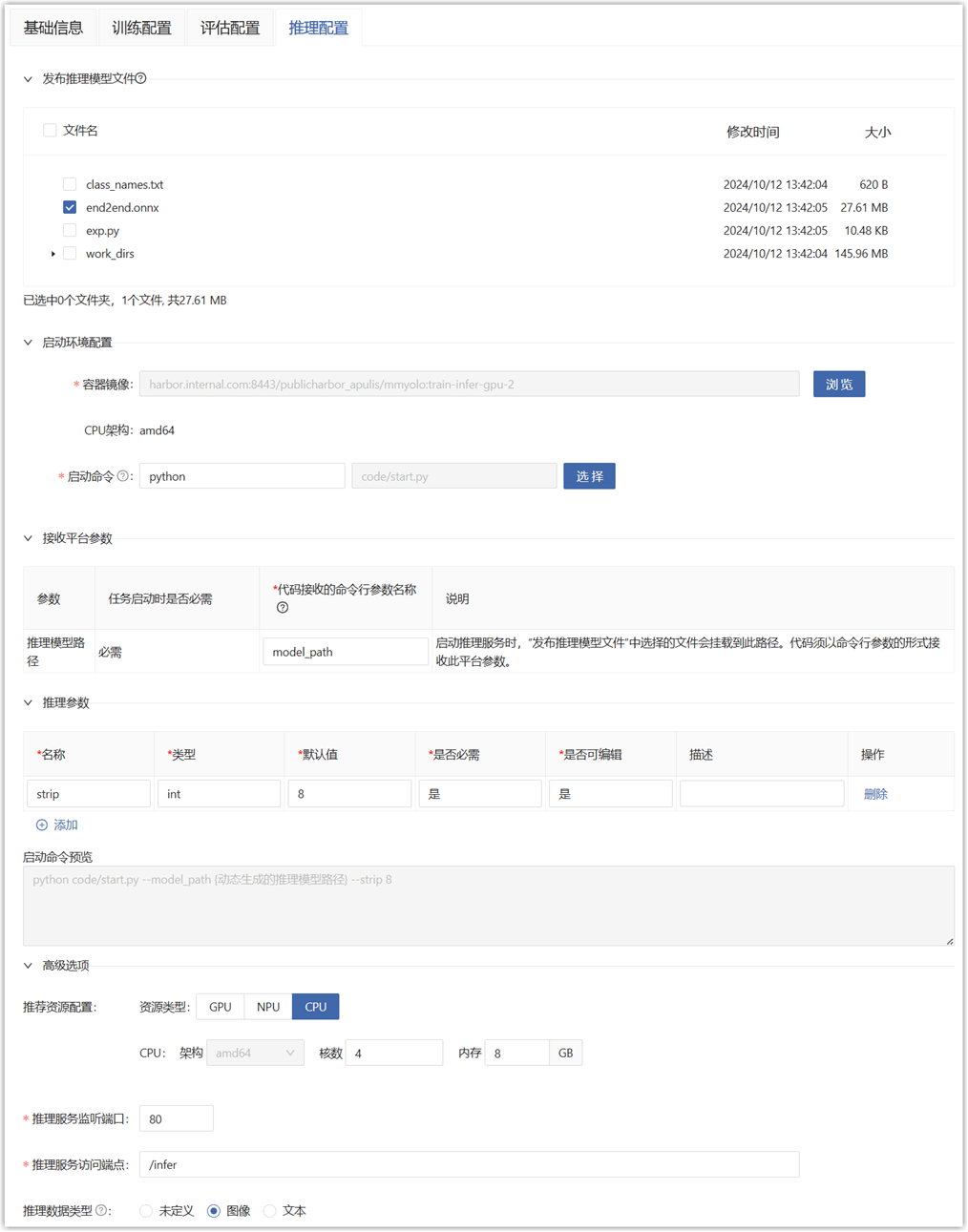
Publish Inference Model File:
Select the model file for inference in the outputs directory of the development environment, such as .ckpt, .pb, .pt, .pth, .onnx, .air, .om, etc. It will be copied to the model directory of the model package during publishing, which is convenient for managing the inference model on the platform. This is not required.
Select the algorithm code file for inference on the "Basic Information" tab, and do not select it here.
When starting the inference service, the model directory will be passed to the startup script in the form of received platform parameters.
- Received Platform Parameters:
- Model Weight Path: The mounting path of the file selected in "Publish Inference Model File".
- Inference Service Listening Port: The port on which the inference service framework listens for HTTP inference requests.
- Inference Service Access Endpoint: The access endpoint where the inference service framework processes HTTP inference requests.
- Inference Data Type: Select the data type input to the inference model. The platform uses different methods to visualize the original inference data and inference results:
- Undefined: The inference result cannot be returned.
- Image: Display the image and graphical inference result.
- Text: Display the text and json.